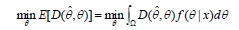1.贝叶斯原理
前面对损失分布的讨论是基于传统的概率论与数理统计方法,根据损失事件具有的独立性和大数法则对损失分布进行理论假设,以及在具有代表性的样本信息基础上,对损失分布的有关参数进行估计和对理论分布进行假设检验但. 在保险实务中,尤其是在非寿险中,往住难以获得足够多的样本信息,或者仅有的损失记录不符合统计样本的理论要求.这时,对损失分布估计就需要加入评估人的主观判断. 并利用新获得的证据修正原来的估计或假设.
贝叶斯推断的基本方法是将关于未知参数的先验信息与样本信息综合分析,再根据贝叶斯原理,得出后验信息,然后根据后验信息去推断未知参数. 贝叶斯估计方法步骤:
(1)选择随机参数的先验分布
(2)建立样本的似然函数
(3)计算参数的后验分布
(4)选择损失函数
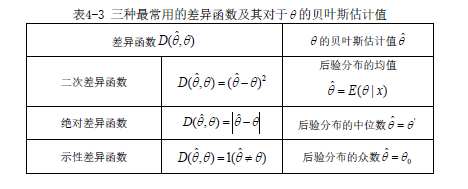
用函数来刻画参数的真实值与估计值间的偏差程度,称这个函数为“差异函数(或损失函数)”,本质上是评估人的“效用函数”.
(5)参数估计
根据所选择的差异函数和参数的后验分布,可求得使差异函数的期望值最小的参数,作为参数的贝叶斯估计值.
2. 先验分布的选择
虽然贝叶斯方法明确地承认选择先验分布的主观性,但并不意味着评估者故意要排斥任何关于未知参数的有用信息,以得到对其概率分布的正确估计. 先验概率只是在评估人缺乏足够样本信息的条件下不得不做出的估计. 在实务中,对于一个不确定事件来说,我们根据过去的经验和知识,总会或多或少地对这一不确定事件有些了解,所有这些有关的信息就称为先验信息. 在先验信息基础上所作的概率估计就是先验概率. 对应的概率分布和概率密度分别是先验分布和先验密度,也可以简单地称其为主观概率.
数理统计方法在理论上是指直接通过从统计实验中得到的样本信息来估计概率分布或密度,而贝叶斯方法既接受先验信息,又不排斥样本信息(如果可能得到的话)等任何可以利用的新证据,因而具有更多的灵活性. 但由于先验概率的设定是否恰当对其结果的影响常常很大. 客观概率论者认为贝叶斯方法缺乏客观性. 好在实践已经证实,贝叶斯方法的确是获得概率分布的一种有效方法,并从实践中总结出了许多设定先验概率的实用方法. 受本书的主题和篇幅所限,我们不在这方面作深入的讨论,只是简单地介绍几种常用方法.
(1) 数理统计方法
如果能够搜集到关于参数取值情况的一些历史数据或样本信息,则可利用第二章中估计标的损失或理赔损失变量分布的数理统计方法,对参数在其取值范围上的先验概率进行估计. 这种方法的一个缺陷就是要求对参数有足够的样本信息.
(2) 主观判断法
可以根据随机事件的客观条件或物理现象来做出概率分布的判断. 例如,古典概型就是根据每一个基本事件的客观物理条件,有理由判断每一基本事件是等可能的. 又如,几何概型也是根据随机事件的客观条件做出的主观判断.
(3) 贝叶斯假设
在应用贝叶斯公式时,需要知道参数的分布——先验分布,然后才能求出的条件分布——后验分布. 贝叶斯认为,当人们对参数没有任何信息时,在它允许变化的范围内机会是均等的,也就是认为的先验分布应是它的取值域上的均匀分布. 这一想法提升为一般性的原则,就称为贝叶斯假设.
贝叶斯假设明显存在两个问题,首先是均匀分布的存在性问题. 当的取值在一个有限区域内,均匀分布是存在的,但在一个无限区域内,均匀分布就不存在了. 其次是均匀分布假设很难与客观实际相符,一般来说,并不一定服从均匀分布.
但是,贝叶斯方法的实践表明,虽然的先验分布是均匀分布,但它的后验分布一般不再是均匀分布了,而的贝叶斯估计只需要的后验分布. 因此,第二个问题就迎刃而解了.
(4) 最大熵准则
从信息论的角度来看,无信息意味着不确定性最大,而熵是度量不确定性的,因此先验分布应具有最大熵才能是无信息的.
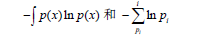

3. 后验分布的确定
从先验概率到后验概率的过程就是直接应用贝叶斯公式的过程,但在具体操作上经常采用一些技巧,其中之一是只考虑与参数有关的先验分布和似然函数,略去计算与参数无关的分母,即直接利用(4.35)式,从而确定后验分布函数形式.
4. 先验分布与后验分布的某些结果
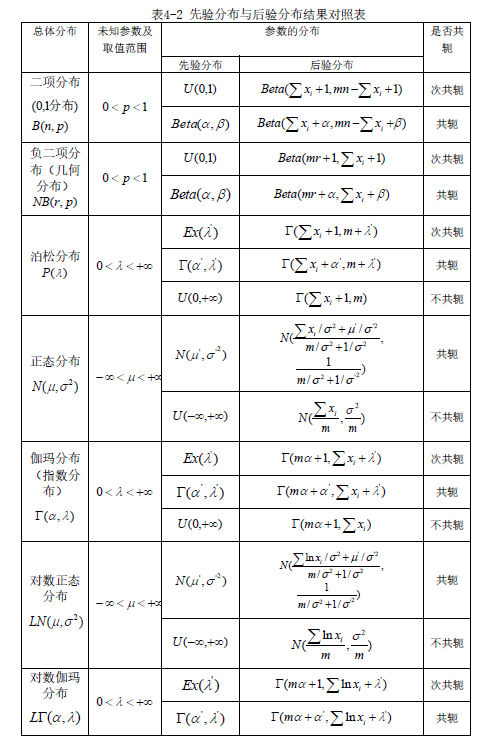
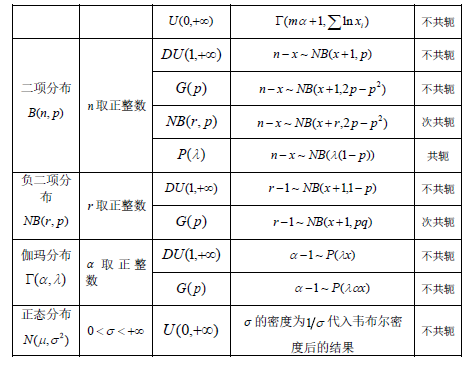
若参数的先验分布与后验分布同属一个分布类型,则称它们为一个共轭对,或者说一个是另一个的共轭分布. 又若后验分布是其先验分布的推广类型(例如,伽玛分布是指数分布的推广类型),则可称它们是次共轭对. 表4-2 中列举了一些常见总体损失分布的未知参数及其先验分布与后验分布的结果. 并由此可以看出它们是否为共轭对.
5. 差异函数与贝叶斯估计量
损失分布的未知参数的贝叶斯估计值仍记为, 由于它是建立在后验分布的基础之上的,所以与先验分布有关且是观察值的函数. 如何确定这个函数呢?数理统计中的矩方法是通过令样本矩等于总体矩来确定它的,这种确定方法隐含着某种主观性,极大似然估计法也有一定的主观性,而贝叶斯估计方法则明确地承认确定估计量方法中的主观性,这种主观性表现为未知参数的估计值与真实值之间的差别对评估者来说究竟有多严重,用什么函数去衡量它. 由于度量与之间的差异程度应该是一个非负数,所以可引用一个非负函数来刻画它,并记为. 最好的估计当然是使差异最小的估计,但由于被看做随机变量,不能直接求的最小值,转而求其期望最小的值.