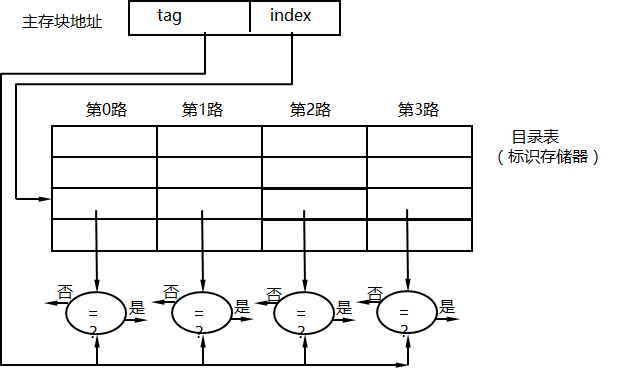
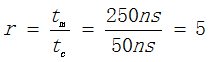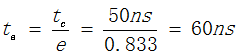地址映射
为了把主存块放到cache中,必须应用某种方法把主存地址定位到cache中,称作地址映射。主要方式有:直接映射方式、相联映射方式、组相联映射方式。
Cache的数据块的大小称为行,用Li表示,其中i=0,1,2,…m-1,共有m=2r行。主存的数据块大小称为块,用Bj表示,其中j=0,1,2,…n-1,共有n=2s块。行与块是等长的,每个块(行)是由k=2w个连续的字组成,字是CPU每次访问存储器时可存取的最小单位。
全相联映射方式
在全相联映象中,主存中任一个块能够映象到Cache中任意一个块的位置。将主存中的一个块的地址(块号)与块的内容(字)一起存于cache的行中,其中块地址存于cache行的标记部分中。
主存地址长度=(s+w)位,寻址单元数=2s+w个字或字节,块大小=行大小=2w个字或字节,主存的块数=2s,Cache的行数=不由地址格式确定,标记大小=s位
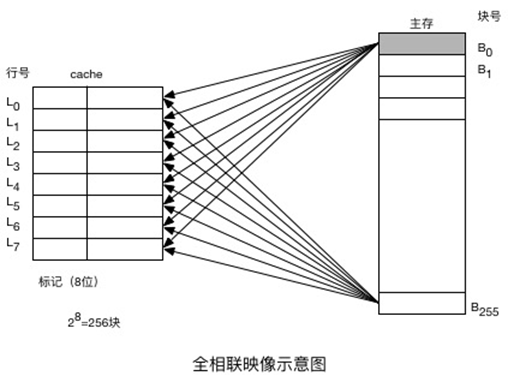
(a)全相联映射示意图
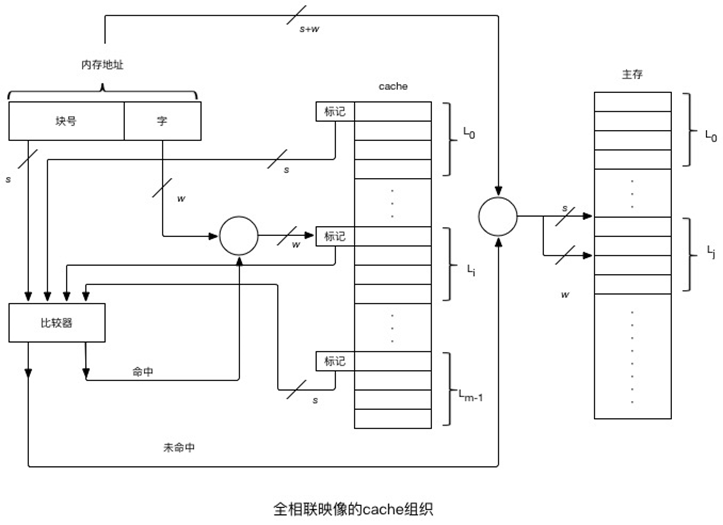
(b)全相联cache的检索过程
图5.4-2 全相联映射的cache组织
检索过程:CPU访存指令制定了一个内存地址(包括主存和cache),为了快速检索,指令中的块号与cache中所有行的标记同时在比较器中进行比较。如果块号命中,则按字地址从cache中读取一个字;如果块号未命中,则按内存地址从主存中读取这个字。
全相联方式的主要缺点是比较器电路难于设计和实现,因此只适合小容量cache采用。
直接映射方式
一种多对一的映射关系,一个主存块只能拷贝到cache一个特定行的位置上。
在直接映象Cache中, 地址被划分未标志、页号和偏移量。页号用于确定数据地址在Cache存储器中的物理位置。
直接映象方式:根据Cache的大小把主存分成若干个区,因此主存容量是Cache容量的若干倍。
i=j mod m
式中:m为cache的总行数
主存地址长度=(s+w)位,寻址单元数=2s+w个字或字节,块大小=行大小=2w个字或字节,主存的块数=2s,Cache的行数=m=2r,标记大小=(s-r)位。

(a)直接映射示意图

(b)直接映射cache的检索过程
图5.4-3 直接映射的cache组织
检索过程:Cache将s位的块地址分为两部分:r位作为cache的行地址,s-r位作为标记(tag)与块数据一起保存在该行。当CPU以一个给定的内存地址访问cache时,首先用r位行号找到cache中的此行,然后用地址中的s-r位标记部分与此行的标记在比较器中做比较;若相符即命中,在cache中找到所需要的块;而后用地址中的最低的w位读取所需要的字;若不符, 则未命中,有主存读取所需要的字。
直接映射方式的优点是硬件简单,成本低。缺点是每个主存块只有一个固定的行位置可存放。效率低下。直接映射方式适合于需要大容量cache的场合,更多的行数可以减少冲突的机会。
组相联映像
组相联映象提供了在性能和价格之间的一种良好平衡。组相联映象是直接映象和相联映象的结合。组内是全相联映象, 组间是直接映象。
这种方式将cache分为u组,每组v行。主存块存放到哪个组是固定的,至于存到该组的哪一行是灵活的,即有如下函数关系:
m=u ╳ v
组号 q=j mod u
块内存地址中 s 位块号划分成两部分:低序的d位(2d=u)用于表示cache组号,高序的s-d位作为标记(tag)与块数据一起存于此组的某行中。
主存地址长度=(s+w)位,寻址单元数=2s+w个字或字节,块大小=行大小=2w个字或字节,主存的块数=2s,每组的行数=k,第组的v=2d,Cache的行数=kv,标记大小=(s-r)位

(a)组相联映射示意图(4组)

(b)组相联cache的检索过程
图5.4-4 组相联的cache组织
cache的每一小框代表的不是“字”而是“行”。当CPU给定一个内存地址访问cache时,首先用块号域的低d位找到cache的相应组,然后将块号域的高s-d位与该组v行中的所有标记同时进行比较。哪行的标记与之相符,哪行即命中。此后再以内存地址的w位字域部分检索此行的具体字,并完成所需要求得存取操作。如果词组没有一行的标记与之相符,即cache未命中,次数需要按内存地址访问内存。
举例:
一个组相联cache由64个行组成,每组4行,主存储器包含4K个块,每块128个字,请表示内存地址的格式。
解:块大小=行大小=2w个字=128=27,所以w=7
每组的行数=k=4
Cache的行数=kv=K╳2d=4╳2d=64, 所以d=4
组数=v=2d=24=16
主存的块数=28=4K=22╳210=212,所以s=12
标记大小(s-d)位=12-4=8位
主存地址长度(s+w)位=12+7=19位
主存寻址单元数2s+w=219