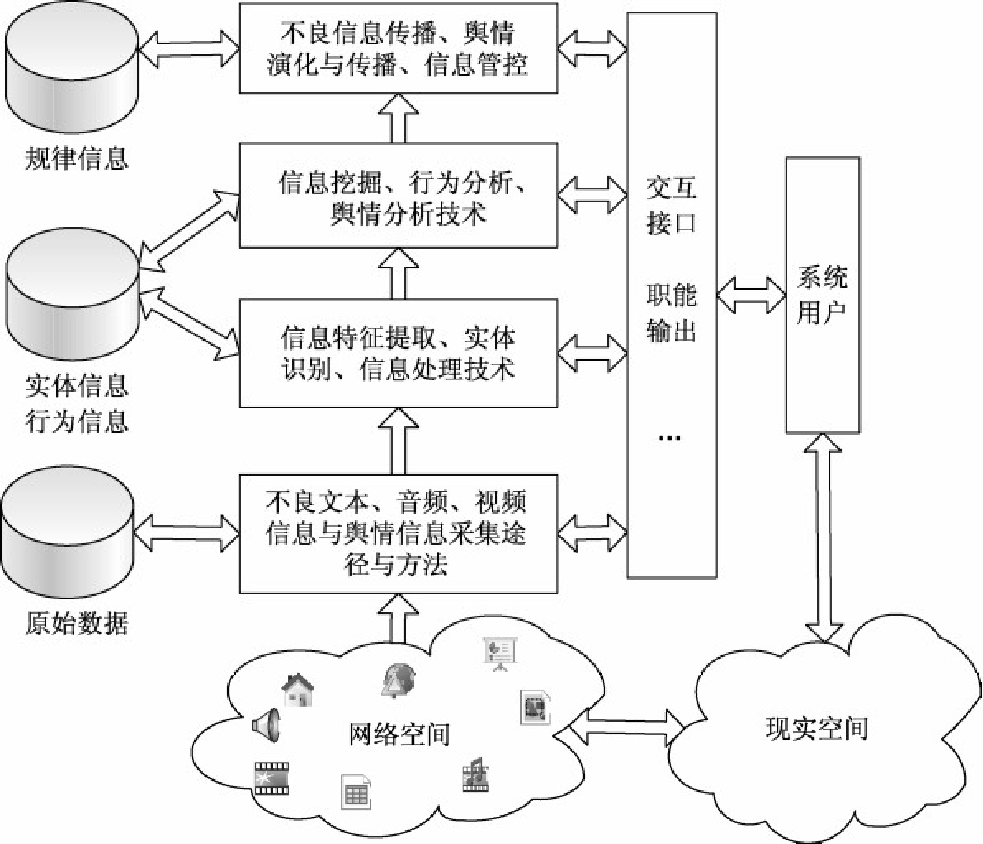
网络内容监控系统技术架构(参考教材P213)
从技术架构上来讲,网络不良信息监控与舆情监控都可以抽象成网络内容监控,都需要依托网络空间海量信息抓取、搜索、文本分析等技术,通过监测相关网页、新闻、论坛、贴吧、博客、微博、微信等类型的网络媒体信息,来发现敏感信息并进行预警。
(1)网页信息直接采集技术
网页分静态和动态两种类型。在进行网页数据直接采集时,需要针对这两类网页的不同特点分别进行主动采集。
静态网页是指预先编译好并存储在服务器上的不含程序和不可交互的网页,常见的有 HTML/ HTM/SHTML 等。此类网页采集较为简单,可以直接连接下载,并在数据库中建立索引。
动态网页,在服务器上部署了有关该网页的程序及数据库,通过异步请求服务器资源,并将其动态更新到网页当中,支持页面状态的动态更新和延迟加载。Ajax 等技术的应用更是加速推动了动态网页的发展,使得动态网页成为主流。由于动态页面采用异步请求机制,页面状态切换不再仅仅依靠网页链接跳转,因而为网页信息采集带来了巨大挑战。此时如果要获取动态页面信息,就需要与服务器交互,通过嵌入式浏览器实现相关脚本模拟,动态请求服务器以获取动态网页内容,避免采集时出现大量页面状态丢失的情况,应采用相关算法来解决事件获取和页面状态标识等问题。 通常采用爬虫模拟浏览器访问的方式爬取。
(2)基于网页结构自动化分析的定点采集技术
定点采集同为主动采集技术,基于人工配置的网站模板,实现网页标题、内容、发布者等元数据的精准解析。
网页的类型不同,网页的条目也各不相同。采集这类网页信息需要自动识别不同网页的条目信息。通常,网页条目数据可以分为网页 URL、新闻主题(标题)、发布时间、正文内容、链接描述文字、论坛统计信息(如点击数等)、论坛跟贴信息、博客导航页等内容。
为了精准获取并解析网页元数据信息,可以利用正则表达式对不同网页结构建立不同的网页分析模型,配置对网络中活跃程度较高的主要新闻、论坛和博客网站的采集模板,实现待采集条目信息的自动识别和获取。当网站格式变化时,需要更新对应的采集模板。
(3)RSS 解析技术
RSS 文件发布即网站输出 RSS 文件之后,文件所含的信息数据就可供其他站点直接调用,由于 RSS 采用标准 XML 格式来描述,网络用户就可以在客户端使用支持 RSS 的聚合工具软件(如 NewzCrawler、SharpReader、FeedDemon 等),不需打开网站内容页面即可阅读该网站输出的 RSS 内容。
(4)元搜索技术
元搜索(Meta-search)是一种通过元搜索引擎(Meta-search Engine)实现的被动采集技术。
网络爬虫(Web Crawler)是采集网页数据的程序。这是一种主动的数据采集方式。
在当今网络信息日益孤岛化的时代,编写爬虫是最主流的信息获取方式。
网络爬虫采集的优点是人工干预较少,且当网站改版时不需更新爬虫程序;缺点是采集到的内容多为非结构化数据,难以准确地实现标题、内容、发布者等元数据的解析。
(1)基本原理
网络爬虫(Web Crawler),又称为网页蜘蛛(Web Spider)、网络机器人(Web Robot),是一种按照一定规则自动抓取网页信息的程序或者脚本,通常驻留在服务器上。在 Web 网页中,既包含可供用户阅读的文字、图片等信息,还包含一些超链接(URL)信息。网络爬虫正是借助这些超链接信息来不断抓取网络上的其他网页。这种信息采集过程很像一个爬虫或蜘蛛在网络上漫游,网络爬虫和网页蜘蛛因此得名。
(2)工作流程
网络爬虫的工作流程是通过给定的一些 URL,从预设的 Web 种子站点开始,抓取 Web 文档,并利用 HTTP 等协议来解析相应文档并采集文档中的信息,寻找该文档中尚未访问过的 URL 作为下一步采集的种子节点,如此反复迭代,直至没有满足条件的新 URL 或者达到指定的采集深度和广度为止。
采集的信息包括标题、长度、文件建立时间、HTML 文件中的各种链接数目等。
(3)爬虫的分类:
根据抓取任务和目标的不同,网络爬虫可分为:
批量型爬虫:批量型爬虫的抓取范围和目标较为明确,可以是网页的设定数量,也可能是消耗时间的设定
增量型爬虫 :增量型爬虫主要用于持续抓取更新的网页,以适应网页的不断变化;
垂直型爬虫 :垂直型爬虫主要用于特定主题内容或者特定行业的网页抓取。
根据抓取模式和部署方式的不同,网络爬虫可大致分为集中式单机爬虫和分布式爬虫 2 类。其中分布式爬虫又分为主从式和对等式两类。
(4)爬虫策略
网络爬虫的抓取策略是指决定待抓取 URL 队列排列顺序的方法。如果将网页之间的指向结构视为一片森林,那么网络爬虫工作流程每个初始种子 URL 就是森林中一棵树的根节点。常见的抓取策略有:深度优先遍历策略、广度优先遍历策略、专业搜索引擎的爬虫策略
(5)常用的爬虫框架和技术
分布式爬虫:Nutch + Hadoop——适合做类似搜索引擎的大型应用。
JAVA爬虫:Crawler4j、WebMagic、WebCollector——相关资料全,适合做多线程爬虫。结合Nutch可以开发分布式爬虫。
Python爬虫——适合做爬虫学习或者开发集中式爬虫。
①Requests库:一个http库,可以执行循环http请求,做些最简单的爬虫
②Scrapy库:一个专业的集中式爬虫框架,:下载器、中间件、调度器、Spider、调试、数据流等等所有功能全部都在这一个框架中。但无法分布式和多线程。
③Selenium库:用于自动化Web应用程序的测试目的框架,也可以用来编写爬虫,优点是可以模拟浏览器访问从而跨越很多反爬机制,缺点是较为复杂,速度慢,爬取规模小
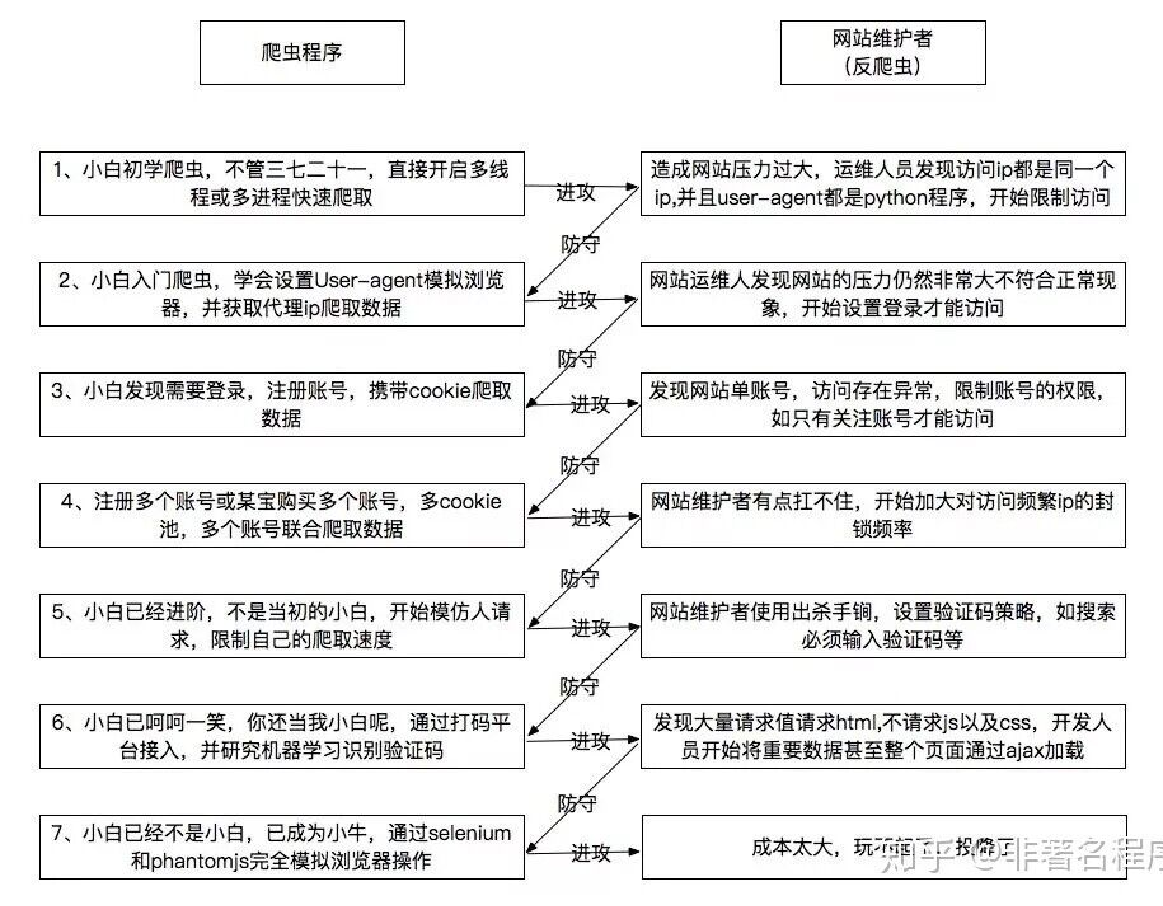
(6)反爬机制
如同很多其他网络安全技术一样,爬虫技术本身是中性的,可以被拿来做善也可以做恶。
由于爬虫机制本身也存在被滥用的风险,因此许多网站也存在反爬虫机制。双方的斗智斗勇从未结束。
因此不存在爬虫写一次就能永远运行的情况。要根据实际情况不断维护。
参考教材P216
信息采集环节完成了对网络上特定或不特定的目标数据源的信息采集工作,接下来需要对采集的信息进行分析处理和存储。
数据处理的根本目的是实现由网页数据信息自动向可供分析监管数据信息的转变。简而言之,这种处理就是从网络中采集的文本、图像、音频、视频等信息中提取适当的特征信息,将其转化成计算机能够分析处理的形式,实现以用户能够理解和接受的方式输出。这个过程包括数据预处理、自动分类、特征提取、自动聚类等。
网络内容监控和不良信息监控涉及到原始数据信息、中间数据信息、分析结果信息以及各种模型库和知识库等,存储内容也涉及结构化数据、半结构化数据、非结构化数据,必须根据具体的信息形态和处理流程,来选用合适的数据存储方式。
当前的不良信息监管系统和舆情监控系统经常采用可视化技术进行信息展示,采用量化统计图表(折线图、柱状图、饼图、蜘蛛图等)、趋势图(基于时间轴的动态图等)、信息图表或动画等多种方式,将数据直观形象地呈现出来,而不仅仅采用文字表达的辅助手段。