5.1 数字音频信号的转换与编码
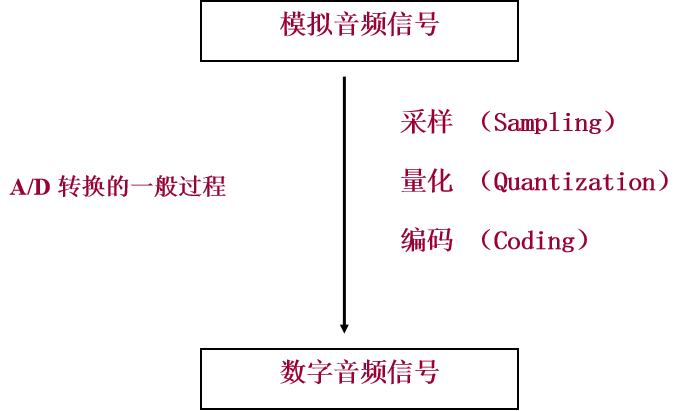
在上一章介绍里的方法里,我们通过话筒拾取到的音频信号都是模拟信号,必须经过模数转换才能输入计算机或者其它数字化音频设备完成后续的处理。模数转换一般是通过计算机音频接口或者专门的A/D转换器来完成的,主要有以下几个步骤:
一、 脉冲编码调制——PCM(Pulse Code Modulation)
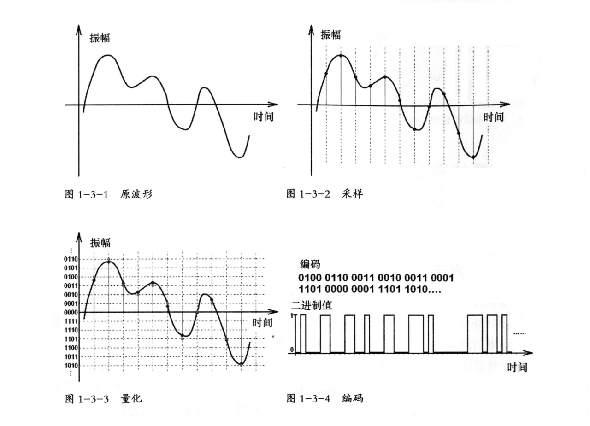
PCM——脉冲编码调制,是目前最基本的一种模数转换方式,也是能够获得最接近于模拟信号波形的一种信号获取与记录方式。它通过对模拟信号等距采样,再按一定的精度记录信号电平获得二进制数据,最后再以一定的编码算法和格式将这些数据记录下来。采样率、采样精度(位深度)和编码方式是影响数字音频信号质量的三个关键因素。
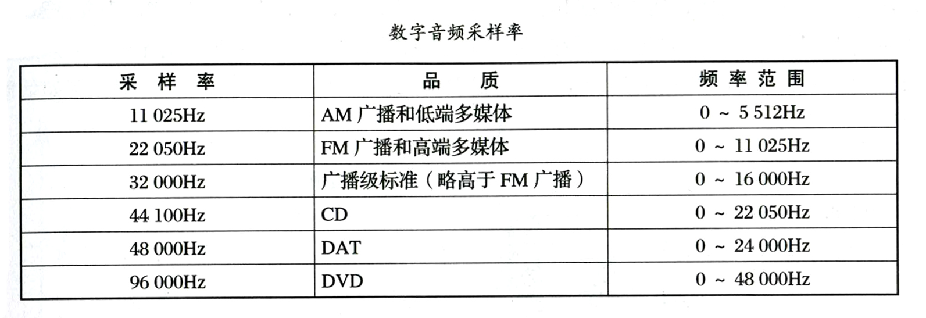
采样频率——22.05kHz、44.1kHz、48kHz、88.2kHz、192kHz。
采样精度——14-bit、 16-bit、18-bit、20-bit、24-bit。
二、采样率
采样率是指每秒音频被分解成多少份数的样本元素,决定了音频文件可以记录的匹普范围。采样率越高,数字音频信号的波形越接近于原始的模拟波形,反之则与原波形差别越大,造成失真。
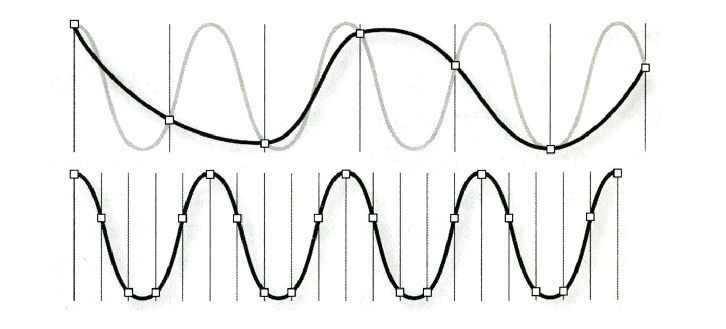
根据采样点位置数据重新绘出波形,因此采样率至少是该音频信号频率的2倍,例如CD的采样率为 44100Hz,所以CD最高可以记录 22050Hz 频率的声音,超过了人类听感的频率上限 ——20000Hz。
数字音频信号的采样率最高值直接受制于负责A/D转换的音频接口的精度水平。目前最高的采样率一般为192KHz。
三、位深度 ( bit )
位深度决定了音频信号的动态范围和精度。当进行采样的时候,每个采样点近似的表示了当前的波形的振幅值。高位深度可以提供更大范围的振幅值,从而产生更为广阔的动态范围,同时也可以降低噪声,提高保真度。
由于数字音频的采样数值不允许为任意值,而是一个固定好的电平值(振幅)的集合,因此集合中的值规定的越多,越细,量化的误差就越小。以CD音质为例,它取16bit位深,每个取样记为,即65536个不同振幅值中的一个。
由于声音的震动是可以朝着正负双向进行的,所以实际应用中规定16位深PCM样值的量化范围为 +32767~-32768,总共仍然是65536个备选级别,专业上将这些级别称为:“量化阶”。
一般来说,数字音频采用16位深最为常见,但有些HiFi系统采用24、32位深,而有些要求较低的场合,如电话,也可能只使用8位深的信号。

不同的位深度能够记录的音频信号的动态范围也是不同的。
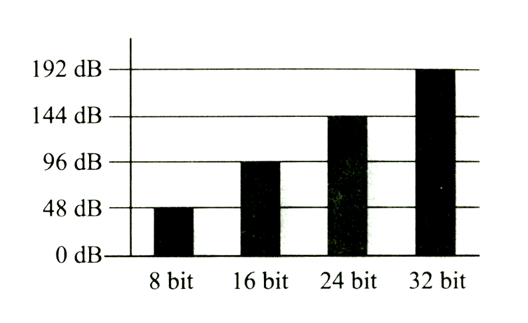
“动态范围”(动态)是表示声音数据中最大信号与非零的最小信号之间的差距的指标,通常用于表征录音系统,录音设备或者录音格式所能够记录的声音信号强度的最大范围。
我们可以通过一个经验公式来估算当前信号的位深度对应的音频数据的可用动态范围:
经验公式:
N×6.02+1.76 dB (N代表PCM采样的位深度)
当前对声音进行数字量化的主流位深度是16bit和24bit,主要是CD和HDCD盘,蓝光盘也可以达到24bit,随着数据存储、压缩技术的发展,更高的位深度比如32bit、48bit应该也会逐渐流行起来。
四、声道数
2 声道, 4声道, 5.1声道, 7.1声道 —— 多列PCM数据在时间轴上保持同步。
五、压缩编码与存储
1.冗余数据压缩的基本原理
采样完成的数字音频信号还必须按照一定的编码方式与文件格式来进行存储。为了减少冗余数据,降低存储容量需求,每一种编码方式往往还伴随有一定的数据压缩的要求(每一种数字音频的存储格式比如wave、mp3、wma、aac、ogg等其实就对应了一种数据压缩、编码以及存储的方法)。
如果把符合PCM规范的采样数据按照时间顺序罗列起来,再加上少量说明其技术指标的信息,就构成了当今计算机上最基本的一种采样音频格式—— 波形 (Wave)文件,常见的扩展名为 .Wav
前面所说的由简单罗列采样信息所构成的wav文件是其中最常见的一种 PCM-wav 格式。
数字音频信号压缩编码的基础是其存在的数据冗余,主要包含时域冗余、频域冗余、听觉冗余等。
在进行数据压缩时,我们要综合考虑音频质量、数据量、计算复杂度等几个方面。
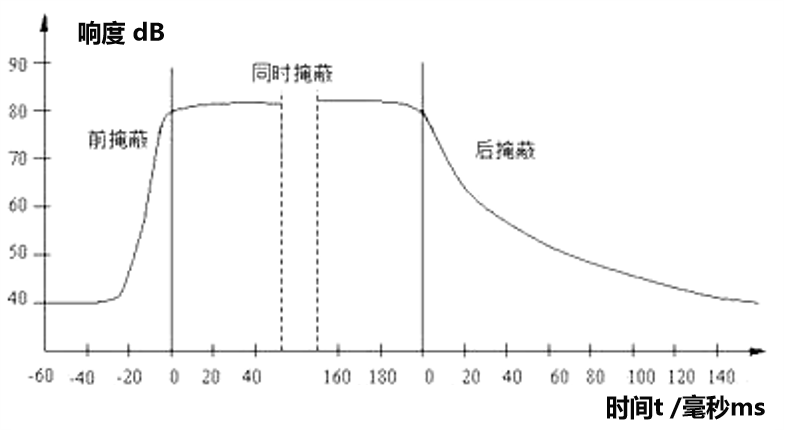
所有的这些去掉数据冗余的算法,都是基于人耳的听觉与心理特性来实现的。主要就是我们在第一章里学习的“响度”以及“掩蔽效应”的相关内容。
比如:
(1)当一个频率的声音能量低于某个响度水平(闻阈)之后,人耳就会听不到。 1.2.1节内容
(2)当一个信号前后有其它能量更大的声音出现的时候,该声音以及频率相近的声音的阈值就会提高很多(掩蔽效应——频域掩蔽) 1.2.7节内容
于是这部分数据就都属于可以被压缩的冗余数据
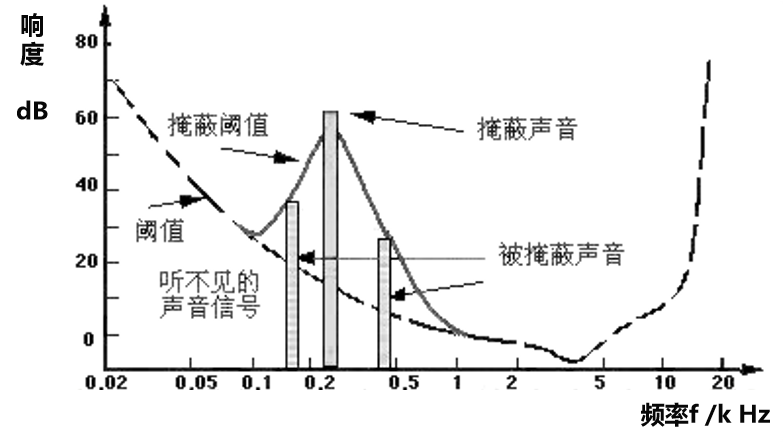
(3)除了相近频率的掩蔽效应以外,时域掩蔽的效果也会造成一定的数据冗余。(或者说可以帮助我们减少记录的数据量)
比如当强信号和弱信号几乎同时出现时,强信号会对弱信号进行掩蔽,具体还可以分为前掩蔽、同时掩蔽和后掩蔽三种,结论我们在1.2.7节里已有提及。
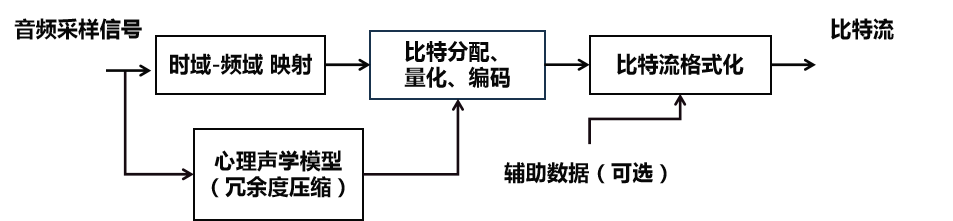
于是,经过采样、量化以后的数据在编码阶段大致经过的处理过程如下图所示:
参考文献:
2.音频压缩编码的类别
(1)基于音频数据统计特性的编码 —— 其典型技术就是波形编码。其目标是使重建音频波形保持原波形的形状。
PCM是最基础的编码方法,它直接进行了A/D转换,没有对数据进行压缩,在它的基础上人们又利用音频样值的幅度分布规律和相邻样值具有相关性等特点,提出了DPCM(差值量化)、APCM(自适应量化)、ADPCM(自适应预测编码)等压缩算法。波形编码压缩比都不大,音频质量好,码率较高。
(2)基于音频的声学参数进行参数编码 —— 可进一步降低数据率。其目标是使重建音频保持原音频的特性。常用音频参数有 共振峰、线性预测系数、滤波器组等等。
这种编码技术的优点是数据码率低,但重建信号质量较差,自然度低。CELP 编码,MPLPC编码 ……
(3)基于人的听觉特性进行编码 —— 从人的听觉系统出发,利用等响度原理、掩蔽效应,设计心理声学模型,从而实现更高效率的数字音频的压缩。
目前的音频压缩方法以MPEG 标准中的音频编码和 Dolby AC-3 最具有影响,我们以它为例做简单介绍。
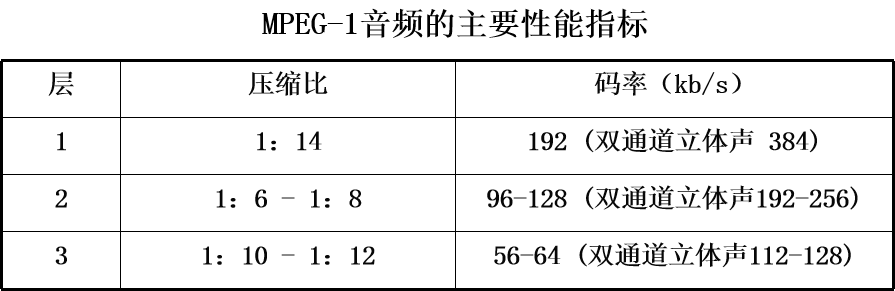
MPEG-1音频分三层,分别为MPEG-1 Layer1,MPEG-Layer2 以及 MPEG-Layer3,并且高层兼容低层。其中第三层被称为MPEG-1 Layer 3,简称MP3。
MPEG-2音频仍沿用MPEG-1 音频的压缩编码技术,仍分为三层,但增加了多声道模式(MPEG-2 AAC),并且三层都增加了16kHz、22.05kHz和23kHz的采样频率。
AC-3 的概念:
利用人的听觉特性,如掩蔽效应(时域 和 频域掩蔽)特性,将压缩编码带来的失真控制在人耳的听觉阈值以下,使人耳觉察不到失真的存在。
虽然 AC-3 初衷是用于HDTV音频压缩压缩编码,但却先在电影业得以实现。1992年,Dolby公司正式推出商品化的 AC-3系统并用于电影《Bat man Return》。目前,AC-3不仅在电影,而且在DVD、HDTV等领域得到广泛应用。
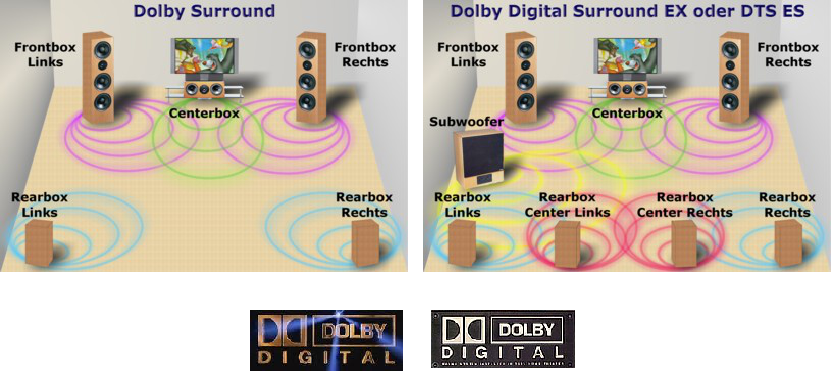
Dolby AC-3提供的环绕声系统由五个全频域声道加一个超低音声道组成,所以被称作5.1个声道。五个声道包括前置的“左声道”、“中置声道”、“右声道”、后置的"左环绕声道"和"右环绕声道"。这些声道的频率范围均为全频域响应3-20000Hz。第六个声道也就是超低音声道包含了一些额外的低音信息,使得一些场景如爆炸、撞击声等的效果更好。由于这个声道的频率响应为3-120Hz,所以称".1"声道。
DSD(Direct Stream Digital)“直接流数字编码”
与典型的PCM数字音频系统CD-DA相比,它具有如下优点:
(1)频响范围宽:CD-DA频响为 50Hz-20.5kHz ,DSD为 DC-100kHz;
(2)性能码位占用比率高:DSD取样频率为CD-DA的64倍,44.1kHz*64=2822400Hz,而每个样点只用1bit量化,而CD-DA的每个样点是用16bit量化,这样每个通道的码率DSD仅为CD-DA的4倍左右,这样的数据量是可以被当前的普通光盘所容纳的。
(3)DSD技术支持5.1环绕声,而CD-DA仅支持双声道。
此外,DSD位流可以直接转化为PCM位流。

