
基于组合关系定义类:组合类
组合类,就是基于组合关系定制的类,组合类的某个数据成员是另一种定制数据类型。例如,家庭类CFamily就是组合类,其家庭成员通过CPerson类来描述;而CPerson类同样是组合类,其数据成员“生日”通过CDate类来描述。代码如下,
class CDate { ……};
class CPerson{
private:
string name; //姓名
CDate birthday; //生日
};
class CFamily {
private:
CPerson father, mother, child; //父亲、母亲、孩子
};
这里,CPerson类的三个对象father、mother、child作为CFamily类的数据成员,描述了一个家庭的三个成员,组合成“家庭”;而CDate类对象birthday,则作为CPerson类的一个数据成员,描述人的生日,与name等成员组合形成“人”。
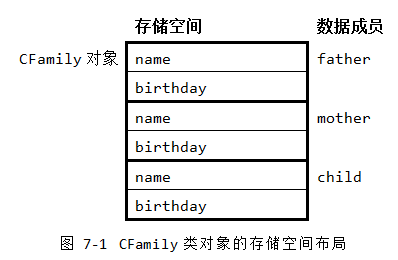
可以推断,一个家庭对象必然包含father、mother、child三个CPerson类对象,称之为对象成员或者子对象。进而,每个CPerson类对象又必然包含一个CDate类的子对象birthday。在图 7‑1中,就给出了CFamily对象的存储空间布局。
组合对象的构造和析构
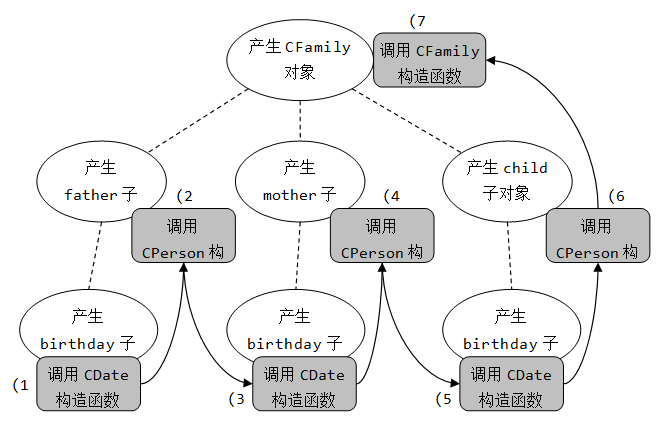
可见,产生一个CFamily对象,必然会产生三个CPerson子对象;而产生每个CPerson子对象,必然会产生一个CDate子对象。
对象的产生会调用构造函数。因此,产生一个CFamily对象,会调用1次CFamily类的构造函数,3次CPerson类的构造函数以及3次CDate类的构造函数。
例如,如下代码会产生家庭对象fm,调用CFamily类对象成员的构造函数以及CFamily类自身的默认构造函数。
CFamily fm; //产生一个CFamily对象
构造函数的调用顺序是先别人后自己:
(1)调用CDate类的默认构造函数,产生father子对象的birday子对象;
(2)调用CPerson类的默认构造函数,产生father子对象;
(3)调用CDate类的默认构造函数,产生mother子对象的birday子对象;
(4)调用CPerson类的默认构造函数,产生mother子对象;
(5)调用CDate类的默认构造函数,产生child子对象的birday子对象;
(6)调用CPerson类的默认构造函数,产生child子对象;
(7)调用CFamily类的默认构造函数,产生fm对象。
同理,CFamily对象的死亡,则会按照先自己后别人的顺序调用析构函数:
(1)调用CFamily类的析构函数,析构CFamily类对象fm;
(2)调用CPerson类的析构函数,析构child子对象;
(3)调用CDate类的析构函数,析构child子对象的birthday子对象;
(4)调用CPerson类的析构函数,析构mother子对象;
(5)调用CDate类的析构函数,析构mother子对象的birthday子对象;
(6)调用CPerson类的析构函数,析构father子对象;
(7)调用CDate类的析构函数,析构father子对象的birthday子对象;
总之,本着“产生你先来,送死我先去”的大无畏英雄主义精神,组合类对象在产生时,总是会首先调用对象成员的构造函数,然后再调用自身的构造函数。反之,组合类对象在消亡时,会首先调用自身的析构函数,然后再析构对象成员。
对象成员之间构造和析构的顺序,按照它们在类体中声明的顺序进行。
组合对象中子对象的显式初始化
在上面CFamily类的例子中,子对象都是通过调用默认构造函数进行初始化的,或者是我们定义的默认构造函数,或者是语言自己合成的默认构造函数。
但是,如果对象成员根本就没有默认构造函数,则会导致编译错误:error C2512: 'CXXX': no appropriate default constructor available。例如,
class CPerson{ //CPerson类没有默认构造函数
private:
string name;
CDate birthday;
public:
CPerson(stringnm) : name(nm) { }
};
class CFamily {
private:
CPerson father, mother, child;
};
intmain() {
CFamily fm; //错误,没有合适的默认构造函数
return 0;
}
CFamily对象fm的产生需要调用CPerson类的默认构造函数,然而CPerson类只有一个单参数构造函数,没有给出默认构造函数,而且语言也不会提供合成的默认构造函数,故编译错误。纠正办法是重载CFamily类的默认构造函数,在其初始化列表中显式地调用子对象合适的构造函数。下面就是修正后的CFamily类:
class CFamily {
……
public:
CFamily(): father("Dadi"),mother("Mumi"), child("Kidi") { }
};
intmain() {
CFamily fm; //正确,有了合适的默认构造函数
return 0;
}
黑体标注的是初始化列表,在初始化列表中显式调用了各个子对象的构造函数。
当然,如果希望在产生CFamily对象时自由设定家庭成员的名字,则可以重载CFamily的构造函数,在初始化列表中显式调用子对象的构造函数。例如,
class CFamily {
……
public:
CFamily() : father("Dadi"),mother("Mumi"), child("Kidi") {}
CFamily(string fn, string mn, string cn)
: child(cn),father(fn), mother(mn) { }
};
intmain() { CFamily fm("Leo", "Cristina", "NN"); }
在初始化列表中构造函数的调用顺序是:child(cn)、father(fn)、mother(mn),但子对象实际的构造顺序却是:father(fn)、mother(mn)、child(cn)。
这是因为,C++语言约定:对象成员构造产生以及析构死亡的顺序,以它们在类体中声明的顺序为准,与它们在初始化列表中的调用顺序没有关系。

