综合项目:文本词频统计
为了深入理解数据结构的使用方法,我们来做一个词频统计(文章中每个词出现的次数)。首先需要下载一个文本(例如:哈姆雷特),请到本平台“资料”下载hamlet.txt,放置到桌面。(注意文件存放路径的表示)
在开始动手前,我们先学习一些必要的知识。

现在我们使用split方法将字符串中的每个单词分开,得到独立的单词:

接下来是词频统计。
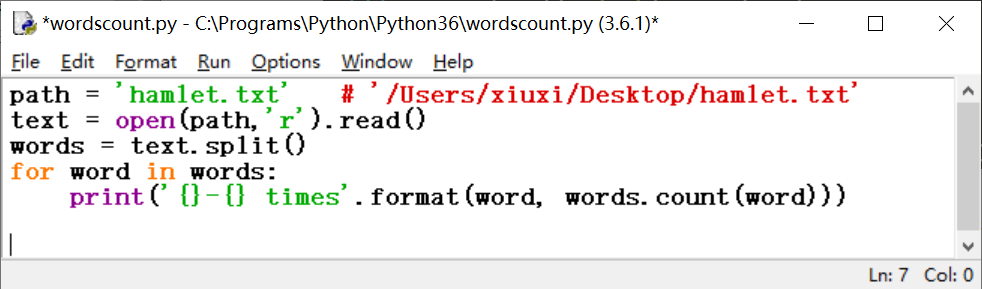
结果出来了,但看起来并不理想。
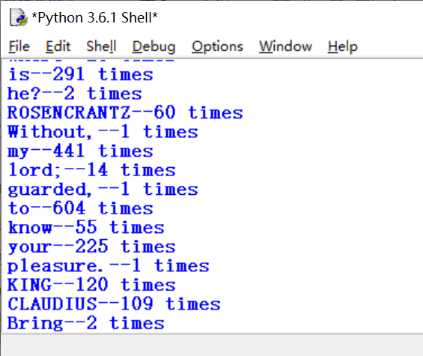
部分结果截图
仔细观察得出结论:

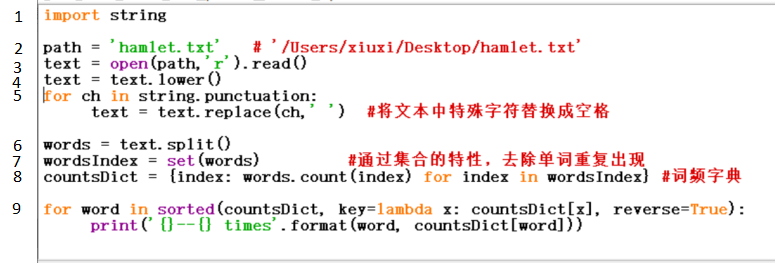
第1行:引入一个新的模块string 。你可以试试打印出string.punctuation,其实它就是包含了所有的英文标点符号:!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~
第4行:在将本文中的字符全转化为小写;
第5行:将文本中的标点符号替代成空格
第7行:将列表用set函数转换成集合,自动去除掉了其中所有重复的元素;
第8行: 创建一个以单词为键(key)出现频率为值(value)的字典;
第9行:打印整理后的函数,其中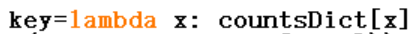 称为lambada表达式,可以暂且理解为以字典中的值为排序的参数。
称为lambada表达式,可以暂且理解为以字典中的值为排序的参数。
运行后部分截图:
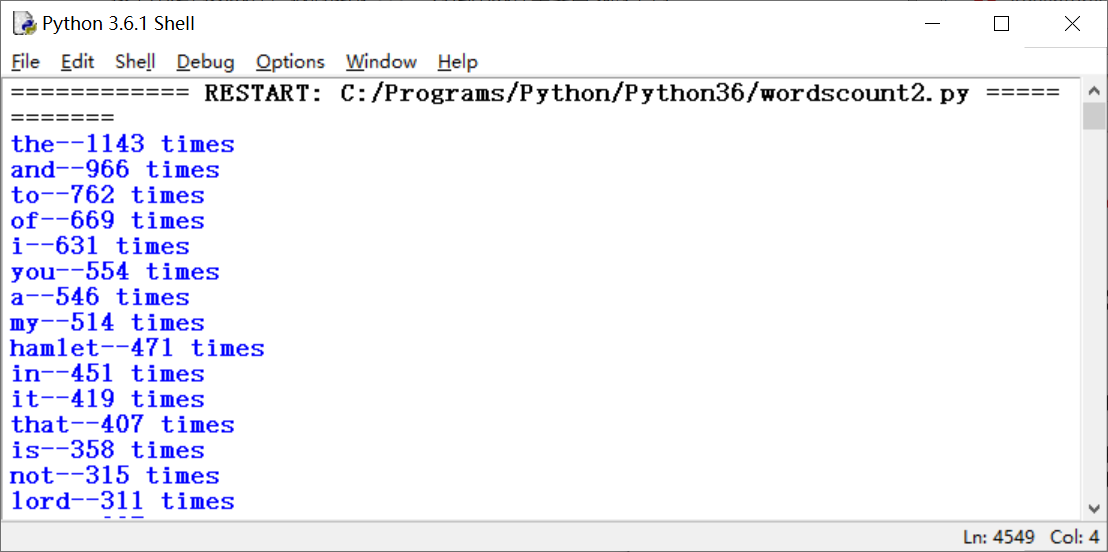
文本词频Top10统计
关于词频Top10统计的解说,可观看视频或阅读以下说明:
https://www.bilibili.com/video/BV1Nb411C7uB?p=171
在很多情况下,我们希望能统计一篇文章或某本书籍中某些词例如名字出现的次数,从而分析文章了解作者意图或文章内容。在对网络信息进行自动检索和归档时,也会遇到类似的问题。这就是”词频统计”问题。
在自动进行词频统计时,我们可以考虑,每遇到一个词,就为其设计一个计数器,每出现一次就对计数器进行累加1。如果把词作为“键”,把计数器的值作为“值”,就构成了字典的键值对<单词>:<出现的次数>,就能很好地解决问题。
通过IPO(input, process, output)描述程序思路:
input输入:从文件中读取一篇文章
process处理:采用字典数据类型结构统计词语出现的频率
output输出:文章中最常出现的10个单词及出现次数
首先,我们以英文文章为例,中文文章例子在我们安排在学习安装第三方库之后再来设计。
1.英文词频统计
英文文本是以空格或标点符号分隔出单词。以Hamlet.txt为输入,考虑到同一单词存在大小写问题,因些首先通过字符串函数lower()将全文字母转为小写; 为方便分隔,把全文的分隔符全部转为空格,这可以使用字符串函数replace()完成。
接着,将调整过的全文(全小写,单词用空格分隔)针对 每个单词进行计数。例如,若一个单词放在word变量中,使用字典类型变量counts在存放单词的次数。当遇到一个单词,如果是新的单词,则使用counts[word]=1; 如果这个单词不是第一次遇到,则使用counts[word]+=1。那么如何判断一个单词是否是新的呢?可以看这个单词是否在counts字典中,使用
if word in counts:
counts[word]= counts[word]+1 # 或者 counts[word]+=1
else:
counts[word]=1
也可以用字典操作中的get()函数来完成同样功能:
counts[word] = counts.get(word,0) + 1
其中,counts.get(word,0) 表示,如果word在counts中,返回对应的次数值,如果不在counts中,返回0。
完成统计后,对统计值 进行从高到低的排序,输出前10个高频词。这个过程通过sort()和lambda函数配合完成。
请查看代码,学习程序设计。

运行结果:

从结果可以看到,高频词大多是一些冠词、代词、连接词等,并不代表文章的意义。为进一步将有“意义”的词提取出来,就需要将这些“无意义”的词排除掉。可以用一个变量excludes存储这些“无意义”的词,excludes={"the", "and","to","of","you","a","i","my","in"}。代码如下:

运行结果:
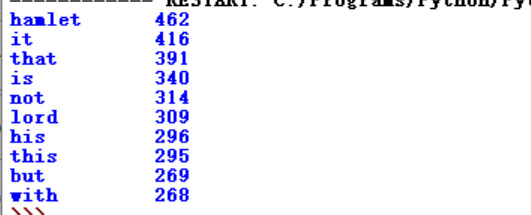
在结果中,我们还是能看到一些”无意义”的词汇,可以重复以上过程,增加excludes中的单词,从而获得满意的结果。
(源代码可在本平台“资料/案例代码/案例10”下载。)


