
(三 )分类 确定对象属于哪个类别。
应用:垃圾邮件检测,图像识别。 算法: SVM,最近邻居,随机森林,......
详细介绍文本分类问题并用Python实现这个过程。
分析社交媒体中的大众情感
鉴别垃圾邮件和非垃圾邮件
自动标注客户问询
将新闻文章按主题分类
注意:本文不深入讲述NLP任务,如果你想先复习下基础知识,可以通过这篇文章
https://www.analyticsvidhya.com/blog/2017/01/ultimate-guide-to-understand-implement-natural-language-processing-codes-in-python/
Pandas:https://pandas.pydata.org/pandas-docs/stable/install.html
Scikit-learn:http://scikit-learn.org/stable/install.html
#导入数据集预处理、特征工程和模型训练所需的库 from sklearn import model_selection, preprocessing, linear_model, naive_bayes, metrics, svm from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer from sklearn import decomposition, ensemble import pandas, xgboost, numpy, textblob, stringfrom keras.preprocessing import text, sequencefrom keras import layers, models, optimizers
https://gist.github.com/kunalj101/ad1d9c58d338e20d09ff26bcc06c4235
https://drive.google.com/drive/folders/0Bz8a_Dbh9Qhbfll6bVpmNUtUcFdjYmF2SEpmZUZUcVNiMUw1TWN6RDV3a0JHT3kxLVhVR2M
#加载数据集
data = open('data/corpus').read()labels, texts = [], []for i, line in enumerate(data.split("\n")):content = line.split()labels.append(content[0])texts.append(content[1])
#创建一个dataframe,列名为text和labeltrain
DF = pandas.DataFrame()trainDF['text'] = textstrainDF['label'] = labels#将数据集分为训练集和验证集 train_x, valid_x, train_y, valid_y = model_selection.train_test_split(trainDF['text'], trainDF['label']) # label编码为目标变量 encoder = preprocessing.LabelEncoder()train_y = encoder.fit_transform(train_y)valid_y = encoder.fit_transform(valid_y)
计数向量作为特征
TF-IDF向量作为特征
单个词语级别
多个词语级别(N-Gram)
词性级别
词嵌入作为特征
基于文本/NLP的特征
主题模型作为特征
#创建一个向量计数器对象
count_vect = CountVectorizer(analyzer='word', token_pattern=r'\w{1,}')count_vect.fit(trainDF['text'])
#使用向量计数器对象转换训练集和验证集
xtrain_count = count_vect.transform(train_x)xvalid_count = count_vect.transform(valid_x)词语级别TF-IDF:矩阵代表了每个词语在不同文档中的TF-IDF分数。
N-gram级别TF-IDF: N-grams是多个词语在一起的组合,这个矩阵代表了N-grams的TF-IDF分数。
词性级别TF-IDF:矩阵代表了语料中多个词性的TF-IDF分数。
#词语级tf-idf
tfidf_vect = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}', max_features=5000)
tfidf_vect.fit(trainDF['text'])
xtrain_tfidf = tfidf_vect.transform(train_x)
xvalid_tfidf = tfidf_vect.transform(valid_x)
# ngram 级tf-idf
tfidf_vect_ngram = TfidfVectorizer(analyzer='word', token_pattern=r'\w{1,}', ngram_range=(2,3), max_features=5000)
tfidf_vect_ngram.fit(trainDF['text'])
xtrain_tfidf_ngram = tfidf_vect_ngram.transform(train_x)
xvalid_tfidf_ngram = tfidf_vect_ngram.transform(valid_x)
#词性级tf-idf
tfidf_vect_ngram_chars = TfidfVectorizer(analyzer='char', token_pattern=r'\w{1,}', ngram_range=(2,3), max_features=5000)
tfidf_vect_ngram_chars.fit(trainDF['text'])
xtrain_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(train_x)
xvalid_tfidf_ngram_chars = tfidf_vect_ngram_chars.transform(valid_x)
https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/
#加载预先训练好的词嵌入向量
embeddings_index = {}
for i, line in enumerate(open('data/wiki-news-300d-1M.vec')):
values = line.split()embeddings_index[values[0]] = numpy.asarray(values[1:], dtype='float32') #创建一个分词器token = text.Tokenizer()token.fit_on_texts(trainDF['text'])word_index = token.word_index
#将文本转换为分词序列,并填充它们保证得到相同长度的向量
train_seq_x = sequence.pad_sequences(token.texts_to_sequences(train_x), maxlen=70)valid_seq_x = sequence.pad_sequences(token.texts_to_sequences(valid_x), maxlen=70)
#创建分词嵌入映射embedding_matrix = numpy.zeros((len(word_index) + 1, 300))for word, i in word_index.items():embedding_vector = embeddings_index.get(word)if embedding_vector is not None:embedding_matrix[i] = embedding_vector文档的词语计数—文档中词语的总数量
文档的词性计数—文档中词性的总数量
文档的平均字密度--文件中使用的单词的平均长度
完整文章中的标点符号出现次数--文档中标点符号的总数量
整篇文章中的大写次数—文档中大写单词的数量
完整文章中标题出现的次数—文档中适当的主题(标题)的总数量
词性标注的频率分布
名词数量
动词数量
形容词数量
副词数量
代词数量
trainDF['char_count'] = trainDF['text'].apply(len)trainDF['word_count'] = trainDF['text'].apply(lambda x: len(x.split()))trainDF['word_density'] = trainDF['char_count'] / (trainDF['word_count']+1)trainDF['punctuation_count'] = trainDF['text'].apply(lambda x: len("".join(_ for _ in x if _ in string.punctuation)))trainDF['title_word_count'] = trainDF['text'].apply(lambda x: len([wrd for wrd in x.split() if wrd.istitle()]))trainDF['upper_case_word_count'] = trainDF['text'].apply(lambda x: len([wrd for wrd in x.split() if wrd.isupper()])) trainDF['char_count'] = trainDF['text'].apply(len)trainDF['word_count'] = trainDF['text'].apply(lambda x: len(x.split()))trainDF['word_density'] = trainDF['char_count'] / (trainDF['word_count']+1)trainDF['punctuation_count'] = trainDF['text'].apply(lambda x: len("".join(_ for _ in x if _ in string.punctuation)))trainDF['title_word_count'] = trainDF['text'].apply(lambda x: len([wrd for wrd in x.split() if wrd.istitle()]))trainDF['upper_case_word_count'] = trainDF['text'].apply(lambda x: len([wrd for wrd in x.split() if wrd.isupper()]))pos_family = {'noun' : ['NN','NNS','NNP','NNPS'],'pron' : ['PRP','PRP$','WP','WP$'],'verb' : ['VB','VBD','VBG','VBN','VBP','VBZ'],'adj' : ['JJ','JJR','JJS'],'adv' : ['RB','RBR','RBS','WRB']} #检查和获得特定句子中的单词的词性标签数量def check_pos_tag(x, flag):cnt = 0try:wiki = textblob.TextBlob(x)for tup in wiki.tags:ppo = list(tup)[1]if ppo in pos_family[flag]:cnt += 1except:passreturn cnt trainDF['noun_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'noun'))trainDF['verb_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'verb'))trainDF['adj_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'adj'))trainDF['adv_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'adv'))trainDF['pron_count'] = trainDF['text'].apply(lambda x: check_pos_tag(x, 'pron'))https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/
#训练主题模型lda_model = decomposition.LatentDirichletAllocation(n_components=20, learning_method='online', max_iter=20)X_topics = lda_model.fit_transform(xtrain_count)topic_word = lda_model.components_vocab = count_vect.get_feature_names() #可视化主题模型n_top_words = 10topic_summaries = []for i, topic_dist in enumerate(topic_word):topic_words = numpy.array(vocab)[numpy.argsort(topic_dist)][:-(n_top_words+1):-1]topic_summaries.append(' '.join(topic_words)朴素贝叶斯分类器
线性分类器
支持向量机(SVM)
Bagging Models
Boosting Models
浅层神经网络
深层神经网络
卷积神经网络(CNN)
LSTM
GRU
双向RNN
循环卷积神经网络(RCNN)
其它深层神经网络的变种
def train_model(classifier, feature_vector_train, label, feature_vector_valid, is_neural_net=False):# fit the training dataset on the classifierclassifier.fit(feature_vector_train, label) # predict the labels on validation datasetpredictions = classifier.predict(feature_vector_valid) if is_neural_net:predictions = predictions.argmax(axis=-1) return metrics.accuracy_score(predictions, valid_y)
A Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature
#特征为计数向量的朴素贝叶斯accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_count, train_y, xvalid_count)print "NB, Count Vectors: ", accuracy #特征为词语级别TF-IDF向量的朴素贝叶斯accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_tfidf, train_y, xvalid_tfidf)print "NB, WordLevel TF-IDF: ", accuracy #特征为多个词语级别TF-IDF向量的朴素贝叶斯accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram)print "NB, N-Gram Vectors: ", accuracy #特征为词性级别TF-IDF向量的朴素贝叶斯accuracy = train_model(naive_bayes.MultinomialNB(), xtrain_tfidf_ngram_chars, train_y, xvalid_tfidf_ngram_chars)print "NB, CharLevel Vectors: ", accuracy#输出结果NB, Count Vectors: 0.7004NB, WordLevel TF-IDF: 0.7024NB, N-Gram Vectors: 0.5344NB, CharLevel Vectors: 0.6872
https://www.analyticsvidhya.com/blog/2015/10/basics-logistic-regression/
# Linear Classifier on Count Vectorsaccuracy = train_model(linear_model.LogisticRegression(), xtrain_count, train_y, xvalid_count)print "LR, Count Vectors: ", accuracy #特征为词语级别TF-IDF向量的线性分类器accuracy = train_model(linear_model.LogisticRegression(), xtrain_tfidf, train_y, xvalid_tfidf)print "LR, WordLevel TF-IDF: ", accuracy #特征为多个词语级别TF-IDF向量的线性分类器accuracy = train_model(linear_model.LogisticRegression(), xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram)print "LR, N-Gram Vectors: ", accuracy #特征为词性级别TF-IDF向量的线性分类器accuracy = train_model(linear_model.LogisticRegression(), xtrain_tfidf_ngram_chars, train_y, xvalid_tfidf_ngram_chars)print "LR, CharLevel Vectors: ", accuracy#输出结果LR, Count Vectors: 0.7048LR, WordLevel TF-IDF: 0.7056LR, N-Gram Vectors: 0.4896LR, CharLevel Vectors: 0.7012
https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/
#特征为多个词语级别TF-IDF向量的SVMaccuracy = train_model(svm.SVC(), xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram)print "SVM, N-Gram Vectors: ", accuracy#输出结果SVM, N-Gram Vectors: 0.5296
https://www.analyticsvidhya.com/blog/2014/06/introduction-random-forest-simplified/
#特征为计数向量的RF
accuracy = train_model(ensemble.RandomForestClassifier(), xtrain_count, train_y, xvalid_count)
print "RF, Count Vectors: ", accuracy
#特征为词语级别TF-IDF向量的RF
accuracy = train_model(ensemble.RandomForestClassifier(), xtrain_tfidf, train_y, xvalid_tfidf)
print "RF, WordLevel TF-IDF: ", accuracy
#输出结果
RF, Count Vectors: 0.6972
RF, WordLevel TF-IDF: 0.6988
https://www.analyticsvidhya.com/blog/2016/01/xgboost-algorithm-easy-steps/
#特征为计数向量的Xgboost
accuracy = train_model(xgboost.XGBClassifier(), xtrain_count.tocsc(), train_y, xvalid_count.tocsc())
print "Xgb, Count Vectors: ", accuracy
#特征为词语级别TF-IDF向量的Xgboost
accuracy = train_model(xgboost.XGBClassifier(), xtrain_tfidf.tocsc(), train_y, xvalid_tfidf.tocsc())
print "Xgb, WordLevel TF-IDF: ", accuracy
#特征为词性级别TF-IDF向量的Xgboost
accuracy = train_model(xgboost.XGBClassifier(), xtrain_tfidf_ngram_chars.tocsc(), train_y, xvalid_tfidf_ngram_chars.tocsc())
print "Xgb, CharLevel Vectors: ", accuracy
#输出结果
Xgb, Count Vectors: 0.6324
Xgb, WordLevel TF-IDF: 0.6364
Xgb, CharLevel Vectors: 0.6548
https://www.analyticsvidhya.com/blog/2017/05/neural-network-from-scratch-in-python-and-r/

def create_model_architecture(input_size):
# create input layer
input_layer = layers.Input((input_size, ), sparse=True)
# create hidden layer
hidden_layer = layers.Dense(100, activation="relu")(input_layer)
# create output layer
output_layer = layers.Dense(1, activation="sigmoid")(hidden_layer)
classifier = models.Model(inputs = input_layer, outputs = output_layer)
classifier.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return classifier
classifier = create_model_architecture(xtrain_tfidf_ngram.shape[1])
accuracy = train_model(classifier, xtrain_tfidf_ngram, train_y, xvalid_tfidf_ngram, is_neural_net=True)
print "NN, Ngram Level TF IDF Vectors", accuracy
#输出结果:
Epoch 1/1
7500/7500 [==============================] - 1s 67us/step - loss: 0.6909
NN, Ngram Level TF IDF Vectors 0.5296
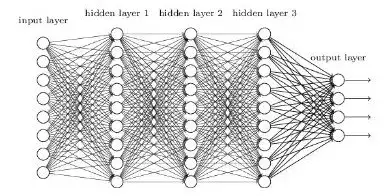
卷积神经网络

https://www.analyticsvidhya.com/blog/2017/06/architecture-of-convolutional-neural-networks-simplified-demystified/
def create_cnn():
# Add an Input Layer
input_layer = layers.Input((70, ))
# Add the word embedding Layer
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
# Add the convolutional Layer
conv_layer = layers.Convolution1D(100, 3, activation="relu")(embedding_layer)
# Add the pooling Layer
pooling_layer = layers.GlobalMaxPool1D()(conv_layer)
# Add the output Layers
output_layer1 = layers.Dense(50, activation="relu")(pooling_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
# Compile the model
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_cnn()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "CNN, Word Embeddings", accuracy
#输出结果
Epoch 1/1
7500/7500 [==============================] - 12s 2ms/step - loss: 0.5847
CNN, Word Embeddings 0.5296
循环神经网络-LSTM
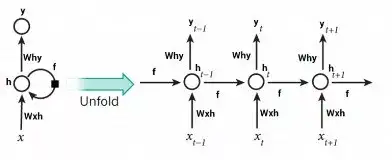
https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/
def create_rnn_lstm():
# Add an Input Layer
input_layer = layers.Input((70, ))
# Add the word embedding Layer
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
# Add the LSTM Layer
lstm_layer = layers.LSTM(100)(embedding_layer)
# Add the output Layers
output_layer1 = layers.Dense(50, activation="relu")(lstm_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
# Compile the model
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_rnn_lstm()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "RNN-LSTM, Word Embeddings", accuracy
#输出结果
Epoch 1/1
7500/7500 [==============================] - 22s 3ms/step - loss: 0.6899
RNN-LSTM, Word Embeddings 0.5124
循环神经网络-GRU
defcreate_rnn_gru():
# Add an Input Layer
input_layer = layers.Input((70, ))
# Add the word embedding Layer
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
# Add the GRU Layer
lstm_layer = layers.GRU(100)(embedding_layer)
# Add the output Layers
output_layer1 = layers.Dense(50, activation="relu")(lstm_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
# Compile the model
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_rnn_gru()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "RNN-GRU, Word Embeddings", accuracy
#输出结果
Epoch 1/1
7500/7500 [==============================] - 19s 3ms/step - loss: 0.6898
RNN-GRU, Word Embeddings 0.5124
双向RNN
defcreate_bidirectional_rnn():
# Add an Input Layer
input_layer = layers.Input((70, ))
# Add the word embedding Layer
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
# Add the LSTM Layer
lstm_layer = layers.Bidirectional(layers.GRU(100))(embedding_layer)
# Add the output Layers
output_layer1 = layers.Dense(50, activation="relu")(lstm_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
# Compile the model
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_bidirectional_rnn()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "RNN-Bidirectional, Word Embeddings", accuracy
#输出结果
Epoch 1/1
7500/7500 [==============================] - 32s 4ms/step - loss: 0.6889
RNN-Bidirectional, Word Embeddings 0.5124
循环卷积神经网络
层次化注意力网络(Sequence to Sequence Models with Attention)
具有注意力机制的seq2seq(Sequence to Sequence Models with Attention)
双向循环卷积神经网络
更多网络层数的CNNs和RNNs
defcreate_rcnn():
# Add an Input Layer
input_layer = layers.Input((70, ))
# Add the word embedding Layer
embedding_layer = layers.Embedding(len(word_index) + 1, 300, weights=[embedding_matrix], trainable=False)(input_layer)
embedding_layer = layers.SpatialDropout1D(0.3)(embedding_layer)
# Add the recurrent layer
rnn_layer = layers.Bidirectional(layers.GRU(50, return_sequences=True))(embedding_layer)
# Add the convolutional Layer
conv_layer = layers.Convolution1D(100, 3, activation="relu")(embedding_layer)
# Add the pooling Layer
pooling_layer = layers.GlobalMaxPool1D()(conv_layer)
# Add the output Layers
output_layer1 = layers.Dense(50, activation="relu")(pooling_layer)
output_layer1 = layers.Dropout(0.25)(output_layer1)
output_layer2 = layers.Dense(1, activation="sigmoid")(output_layer1)
# Compile the model
model = models.Model(inputs=input_layer, outputs=output_layer2)
model.compile(optimizer=optimizers.Adam(), loss='binary_crossentropy')
return model
classifier = create_rcnn()
accuracy = train_model(classifier, train_seq_x, train_y, valid_seq_x, is_neural_net=True)
print "CNN, Word Embeddings", accuracy
#输出结果
Epoch 1/1
7500/7500 [==============================] - 11s 1ms/step - loss: 0.6902
CNN, Word Embeddings 0.5124
https://www.analyticsvidhya.com/blog/2014/11/text-data-cleaning-steps-python/
https://www.analyticsvidhya.com/blog/2015/08/introduction-ensemble-learning/

