
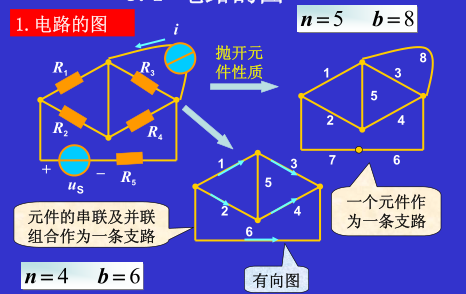

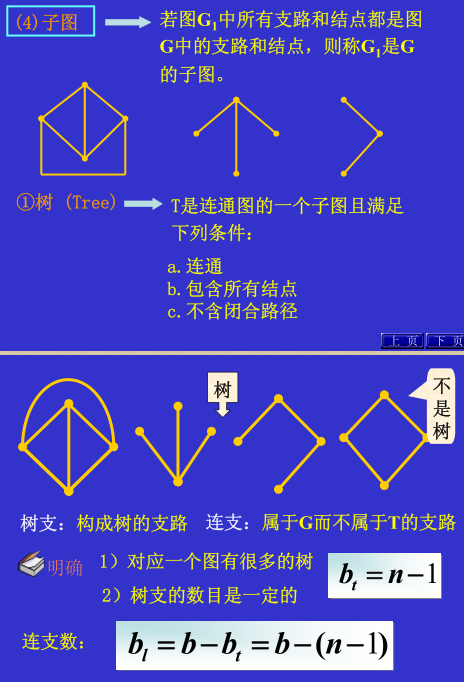
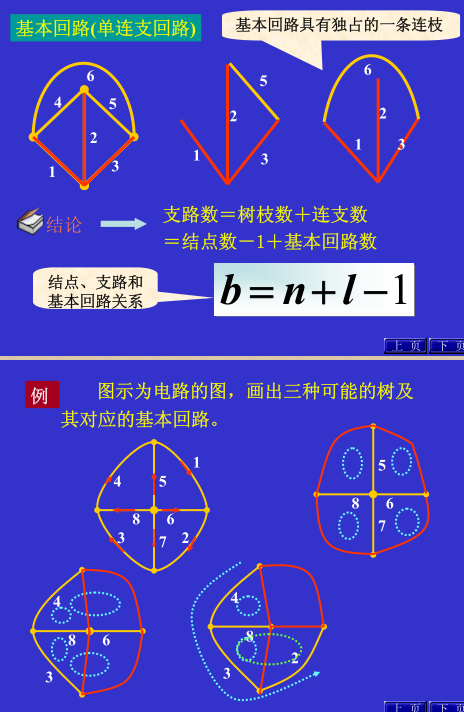
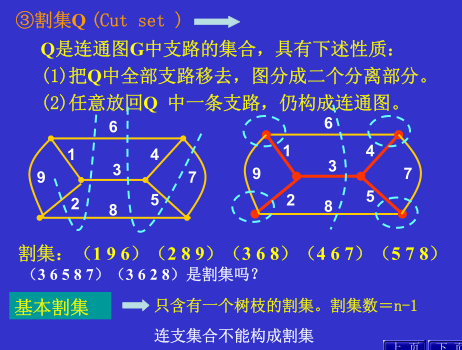
有关图的课外补充知识:图的定义 ,非常有用,不仅在电路、计算机科学技术等领域都广泛的应用,建议同学们专研下。让我们开始吧。
图的定义
背景知识
下面这幅图这就是传说中的七桥问题(哥尼斯堡桥问题)。在哥尼斯堡,普雷格尔河环绕着奈佛夫岛(图中的A岛)。这条河将陆地分成了下面4个区域,该处还有着7座连接这些陆地的桥梁。
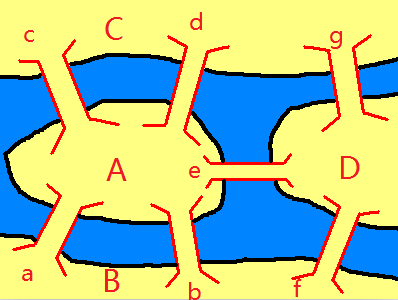
问题是如何从某地出发,依次沿着各个桥,必须经过每座桥且每座桥只能经过1次,最终回到原地。
不知道这个问题且好奇的童鞋现在肯定在忙活着找出来这道题的结果了。是伟大的数学家欧拉(Leonhard Euler)在1736年首次使用图的方法解决了该问题。欧拉将上面的模型转换成了下面这种”图“的形式。
欧拉把顶点的度定义为与该顶点相关联的边的条数,并且他证明了存在从任意点出发,经过所有边恰好一次,并最终回到出发顶点的走法的充分必要条件是:每个顶点的度均为偶数。人们称之为欧拉闭迹(Eulerian walk)。
简要定义
图由顶点(vertex)的集和边(Edge)的集组成。顶点代表了对象,在示意图中我们使用点或圆来表示它;边代表了两个对象的连接关系,在示意图中我们使用连接两顶点的线段来表示。
有时也把边称作弧(arc),如果点对是有序的,那么图就叫做有向的图(有向图)。如果点对是无序的,那么图就叫做无向的图(无向图)。简单的讲,边没有指向性的图叫做无向图,边具有指向性的图叫做有向图。
我们可以给边赋予各式的属性,比如权值(cost)。权值可以表示从一个顶点到另一个顶点的距离,也可以表示一个顶点到另一个顶点说话费的代价(比如时间、金钱等)。一个边上带权值的图称为网络(network)。
如果无向图中从每一个顶点到其他每个顶点都存在一条路径,则称该无向图是连通的(connected)。具有这样性质的有向图称为是强连通的的(strongly connected)。如果有向图不是强连通的,但它的基础图(underlying graph)(也就是其弧上去掉方向说形成的图)是连通的,那么称该有向图是弱连通的(weakly connected)。完全图(complete graph)是其每一对顶点间都存在一条边的图。
所谓入度(indegree)是指的顶点的边的条数。
图的存储表示方式
图主要有3种常用的存储表示方式:邻接矩阵(adjacency matrices),邻接表(adjacency lists),邻接多重表(adjacency multilists)。
邻接矩阵
邻接矩阵使用的二维数组来表示图。表示的是顶点和顶点的关系。
1)因为在无向图中,我们只需要知道顶点和顶点是否是相连的,因此我们只需要将和设置为1或是0表示相连或不相连即可。
2)而在有向图中,我们只需要知道是否有从顶点到顶点的边,因此如果顶点有一条指向顶点的边,那么就设为1,否则设为0。有向图与无向图不同,并不需要满足。
3)在带权值的图中,表示的是顶点i到顶点j的边的权值。由于在边不存在的情况下,如果将设为0,就无法和权值为0的情况区分开来,因此选取适当的较大的常数INF(只要能和普通的权值区别开来就可以了),然后令就好了。当然,在无向图中还是要保持。在一条边上有多种不带权值的情况下,定义多个同样的数组,或者是使用结构体或类作为数组的元素,就可以和原来一样对图进行处理了。使用这种存储方式,可以很方便地判断任意两个顶点之间是否有边以及确定顶点的度,这也是这种表示法最大的优势。这种表示法中扫描所有边至少需要时间,因为必须检查矩阵中的个元素才能确定图中边的条数(邻接矩阵对角线上的n个元素都是0,因此不用检查。又因为无向图的邻接矩阵是对称的,实际只需检查邻接矩阵的一半元素)。通常把边很少的图成为稀疏图(sparse graphs)。
邻接表
如果用邻接矩阵表示稀疏图就会浪费大量内存空间,而用链接表,则是通过把顶点所能到的顶点的边保存在链表中来表示图,这样就只需要的内存空间。
而所谓的邻接表,就是用n个链表代替邻接矩阵中的n行。链表中的结点结构至少要包含一个顶点域和一个链域。对于任意给定的链表i,链表中的结点就是与顶点i相邻的所有顶点。
在无向图的邻接表存储表示中,每一条边 都表示为两项:一项在顶点 的邻接表中,而另一项在顶点 的邻接表中。在多重表中,各链表中的结点可以被几个链表共享,此时图中的每一条边只对应于一个结点,而这个结点出现在该边所关联的两个顶点的每个邻接链表中。
拓扑排序
拓扑排序(topological sort)是对有向无环图的顶点的一种排序,它使得如果存在一条从vi到vj的路径,那么在排序中vj出现在vi的后面。正是由于这个特性,如果图含有回路,那么拓扑排序是不可能的。求拓扑排序算法的一种简单方式:选中一个没有入边的顶点,显示出该点,并将它和它的边一起从图中删除,然后对图的其余部分应用同样的方法处理。
假设每一个顶点的入度被存储且图被读入一个邻接表中,下面的代码则可以生成一个拓扑排序。
最短路径算法
单源最短路径问题:给定一个加权图G=(V,E)和一个特定顶点s作为输入,找出从s到G中每一个其他点的最短加权路径。
如下图所示,从v1到v6的最短加权路径的值为6(),从到的最短加权路径的值为5()。
下面这个图从v5到v4的最短加权路径可就有意思了,它是1么?不是。按照的路径走则是一条更短的路径了,因为这是带负值回路的图。而由于带负值而引入的循环,这个循环叫做负值回路(negative-cost cycle),当它出现在图中时,最短路径问题就是不确定的了。有负值的边未必不好,但它们明显使问题更加难了。
当未指明所讨论的是加权路径还是无权路径时,如果图是加权的,那么路径就是加权的。
Dijkstra算法
前面的广度优先搜索中的图是无权图,而如果一旦变成了加权图,那么问题就变得困难起来了。
对于每个顶点,我们标记为known以及unknown,和上面一样,还得有一个距离的。与无权最短路径一样,Dijkstra算法也是按阶段进行,在每个阶段选择一个顶点v,它在所有unknown顶点中具有最小的,同时算法声明从到的最短路径是known的。然后紧接着,不断的进行下去即可。
图中已经对权重做好了标记,以作为切入点,因此初始情况如下左图。
此时已经是known的了,而其有2个邻接点和,因此可以调整为如下右图。正无穷图标标识没有连通。表示前一个邻接点。
毫无疑问这里会接下来走到v4去,因为v4的权重为1比v2的权重为2要小。调整为如下左图。
可能你已经看到了上图中的右图而好奇为什么下一步是,但是根本不能走到。因为能够走到的,比如,权重从开始一共是3,这比从到还要大。于是就跳转回到了。
下一步便走到了,因为只有值为3的权重,同样的也是,于是它们俩被双双标记为known。如下左图所示。
紧接着走到了,同时下调到了得到了如下右图。至于为什么要做这个调整,是因为此时到的加权为,而到的加权为1,所以就有了这个调整。最后便顺势走到了v6完成了整个Dijkstra算法,它们都已被标记为known。
在后面还将会有一种斐波那契堆,针对Dijkstra算法做了优化,欢迎大家的继续关注。
具有负边值得图
而如果一个图具有负的边值,那么Dijkstra算法就行不通了。这是因为一个顶点u被声明为known后,那就可能从某个另外的unknown顶点v有一条回到u的负的路径。而“回到”就意味着循环,前面的例子中我们已经知道了循环是多么的……
问题并非没有解决的办法,如果我们有一个常数X,将其加到每一条边的值上,这样除去负的边,再计算新图的最短路径,最后把结果应用到原图上。然后这个解决方案也是布满了荆棘,因为居多许多条边的路径变得比那些具有很少边的路径权重更重了。如果我们将s放到队列中,然后再每一个阶段让一个顶点v出队,找出所有与v邻接的顶点w,使得,然后更新到和,并在不在队列中时将它放到队列中,可以为每一个顶点设置一个位(bit)以指示它在队列中出现的情况。
无环图
如果图是无环的,则可以通过改变声明顶点为known的顺序,或者叫做顶点选取法则来改进Dijkstra算法。这种方法通过拓扑排序来选择顶点,由于选择和更新可以在拓扑排序执行的过程中执行,因此新的算法只需要一趟就可以完成。
通过下面这个动作结点图(activity-node graph)来解释什么是关键路径分析(critical path analysis)再合适不过了。一条边表示动作v必须在动作w开始前完成,如前面说描述的那样,这就意味着图必须是无环的。
为了进行这些运算,我们把动作结点图转化成事件结点图(event-node graph),每个事件对应于一个动作和所有与它相关的动作完成。
所以现在我们需要找出事件的最早完成时间,只要找出从第一个事件到最后一关事件的最长路径的长。因为有正值回路(positive-cost cycle)的存在最长路径问题常常是没有意义的。而由于事件结点图是无环图,那就不需要担心回路的问题了,这样一来就不用有所顾忌了。
借助顶点的拓扑排序计算最早完成时间,而最晚完成时间则通过倒转拓扑排序来计算。
而事件结点图中每条边的松弛时间(slack time)代表对应动作可以被延迟而不推迟整体完成的时间量,最早完成时间、最晚完成时间和松弛时间如下所示。
某些动作的松弛时间为0,这些动作是关键性的动作,它们必须按计划结束。至少存在一条完成零-松弛边组成的路径,这样的路径是关键路径(critical path)。
网络流问题
如下左图所示,有一个顶点,称为源点(source);还有一个顶点,称为汇点(sink)。对于顶点,它最大流出2,因此它的最大流入为2,如下右图所示。而的最大流也就是5。
要想计算最大流,同样可是使用前面的思想——分阶段进行。令开始时所有边都没有流,如下中间图所示。我们可以用残余图(residual graph)来表示对于每条边还能再添加上多少流。对于每一条边,可以从容量中减去当前的流而计算出残留的流。
第一步:假设我们选择路径,此时会发出2个单位的流通过这条路径的每一边,如下中间图所示。对比左图,我们做如下约定:一旦注满(使饱和)一条边,例如到和到,就将这条边从残余图(也就是中间图)去掉,如下右图所示。
第二步:接下来选择路径,此时也会发出2个单位的流通过这条路径的每一边,如下中间图所示(只看即可,为上一步说走过的路径)。
第三步:从上图的残余图中我们已经可以看出来最后一步的唯一一种走法了,也就是从。做如下图所示更新。
很显然从无法走到,因此算法至此便终止了。因此正好5个单位的流是最大值。前面的三步我们走的如此顺利,那么问题真的如此简单么?
如果一开始我们选择了,那么算法就会失败了,因为路已经被堵死了。
为了使算法得以成功运作,那么就要让流图中具有以相反方向发送流的路径,如下所示。那么对于如下右图中的残余图而言,从d返回到a的便成了3而非4,这是因为从t流到d的流量是3个单位。现在在残余图中就有a和d之间有2个方向,或者还有1个单位的流可以从导向,或者是3个单位的流导向相反的反向,当然,我们也可以撤销流。
AOV网络
除了一些不能再简单的工程外,所有的工程都可以划分为若干个成为活动(activities)的子工程。比如说大学的课程,得修完了大学英语1才能修大学英语2,也得修完了高等数学才能修线性代数、概率论、离散数学等。将这些作为顶点标记为图时,它便是一个有向图。
顶点表示活动的网(activity on vertex network)或AOV网,是用顶点表示活动或任务,边表示活动或任务之间的优先关系的有向图G。在AOV网络G中,当且仅当从顶点i到j存在一条有向路径,则顶点i称为顶点j的前驱(predecessor);当且仅当 是G中的一条边,则称顶点i为顶点j的直接前驱(immediate predecessor)。如果顶点i是顶点j的前驱,则称顶点j为顶点i的后继(successor);如果顶点i是顶点j的直接前驱,则称顶点为顶点的直接后继。
拓扑排列是由有向图中所有顶点形成一个线性序列,对图中任意两个顶点和,如果顶点是顶点的前驱,则顶点在拓扑序列中排在顶点的前面。
对于拓扑排序问题,所需的操作主要有:
1)判断顶点是否有前驱;
2)删除顶点和关联于该顶点的所有边。
在topsort的声明中,count域用来保存顶点的入度,而link域则是指向邻接表首结点的指针。邻接表中的每个结点又包含了两个域:vertex和link。在输入时,可以方便地设置count域的值。当输入一条边 时,顶点j的count就会加1。用一个栈来保存count值为0的顶点序列。当然也可以使用队列,但栈更容易实现。由于在count域减至0以后,count域就没有用了,所以通过头结点的count域把栈中的各个结点链接起来。
对于topsort的分析:对于具有n个顶点和e条边的AOV网络,第一个for循环的时间开销为。而第二个for循环执行n次。if子句在常数时间内完成;else子句中的for循环时间开销为O(),其中是顶点i的出度。由于这个循环会在每个顶点输出时执行一次,所以总时间为:
因此这个算法的渐进时间为O(e+n),与问题的规模呈线性关系。
AOE网络
AOE网络就是边表示活动的网络(activity on edge network),它的有向边表示在一个工程中所需完成的任务或活动,而顶点表示事件,用来标识某些活动的完成。在AOV网络中,事件高数2完成意味着要先完成高数1;AOE网络中,事件高数2完成意味着已经完成了高数1。也就是说在AOE中,当一个事件发生时,就表明触发该事件的所有活动都已经完成。
在AOE网络中,有些活动可以并行地进行,所以完成整个工程所需的最短时间是从开始顶点到终止顶点的最长路径的长度。关键路径(critical path)就是一条具有最长路径长度的路径。
一个事件可以发生的最早发生时间(earliest time),是从开始顶点到顶点的最长路径的长度。活动的最迟开始时间(latest time),记作,是指在不增加工程工期的前提下,活动能够最迟的开始时间。
关键网络(critical activity)是指满足的活动,一个活动的最迟开始时间与最早开始时间之间的差说明了该活动的关键程度。
最小生成树
一个无向图G的最小生成树(minimum spanning tree)就是由该图的那些连接G的所有顶点的边构成的总值最低的树。最小生成树存在当且仅当G是连通的。
Prim算法
计算最小生成树的一种方法是使其连续地一步一步成长,在每一步中,都要把一个结点当作根并且往上累加边,于是就将关联的顶点加到了增长中的树上。Prim算法和前面求最短路径的Dijkstra算法思想类似,因此和前面一样我们对每一个顶点保留值dv和pv以及一个标记顶点的known或unknown。
Kruskal算法
第二种贪心策略是连续地按照最小的权选择边,并且当所选的边不产生回路时就把它作为取定的边。同样是前面的示例,用Kruskal算法执行如下。Kruskal算法是在处理一个森林——树的集合。下图展示了边被添加到森林中的顺序。当添加到森林中的边足够多时,算法终止,这里算法的作用在于决定边是应该添加还是舍弃。在该算法执行的过程中,两个顶点属于同一个集合当且仅当它们在当前的生成森林(spanning forest)中连通。如果和在同一个集合中,那么连接它们的边就要放弃,因为当它们已经连接的情况下,再添加边就会形成一个回路。如果这两个顶点不在同一个集合中,就应该将这条边加入,并对包含顶点和的两个集合执行一次union操作。这样将保持集合的不变性,因为一旦边添加到生成森林中,若连通到而连通到,这和必然是连通的,因此属于相同的集合。虽然将边排序便于选取,但用线性时间建立一个堆则是更好的想法,此时deleteMin使得边依次得到测试。
Sollin算法
Sollin算法在每一步都为生成树递归地选取若干条边,在每一步处理开始时,说选取的边与图中的所有n个顶点形成一个生成森林。在执行过程中,为森林中的每棵树都选取一条边,与选取的边都是恰有一个顶点在树上且代价最小。由于森林中的两棵树可能选取同一条边,所以需要去掉同一条边被多次选取的情况。在开始时,说选取的边集为空,当最后结果只有一棵树或者再没有边可供选取时,算法就此结束。
深度优先搜索
深度优先搜索(depth-first search)是对前序遍历的推广,对每一个顶点,字段visited被初始化成false,通过哪些尚未被访问的结点递归调用该过程,我们保证不会陷入无限循环。如果图是无向且连通的,或是有向但非强连通的,这种方法可能会访问不到某些结点。此时我们搜索一个未被标记的结点,然后应用深度优先遍历,并继续这个过程直到不存在未标记的结点为止。因为该方法保证每一条边只被访问一次,所以只要使用邻接表,执行遍历的总时间就是。

