
1、数据预处理对数据挖掘过程是至关重要的,工欲善其事必先利其器!
2、预处理——数据清理异常和非法值,联想八项规定,规范我们的行为,做诚实守信的大学生。


数据预处理是数据挖掘过程中的一个重要步骤,尤其是在对包含有噪声、不完整,甚至是不一致数据进行数据挖掘时,更需要进行数据的预处理,以提高数据挖掘对象的质量,并最终达到提高数据挖掘所获模式知识质量的目的。数据预处理主要包括:数据清洗、数据集成、数据变换和数据归约。
(1)数据清洗
数据清洗主要是删除原始数据集中的无关数据、重复数据、平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。
缺失值的处理方法有三种,直接删除记录、数据插补和不处理。其中常用的数据插补方法有:均值或众数插补、固定值插补、最近邻插补、回归方法插补、拉格朗日插值法或牛顿插值法。

(2)数据集成
数据集成就是将来自多个数据源(如:数据库、文件等)数据合并到一起。由于描述同一个概念的属性在不同数据库取不同的名字,在进行数据集成时就常常会引起数据的不一致或冗余。例如:在一个数据库中一个顾客的身份编码为“custom_id”,而在另一个数据库则为“cust_id”。命名的不一致常常也会导致同一属性值的内容不同,如:在一个数据库中一个人的姓取“Bill”,而在另一个数据库中则取“B”。同样大量的数据冗余不仅会降低挖掘速度,而且也会误导挖掘进程。因此除了进行数据清洗之外,在数据集成中还需要注意消除数据的冗余。此外在完成数据集成之后,有时还需要进行数据清洗以便消除可能存在的数据冗余。

(3)数据变换
数据变换主要是对数据进行规范化处理,将数据转换为“适当的”形式,以适用于挖掘任务及算法的需求。
◇简单的函数变换:比如,某班级某次考试的成绩不理想,教师通常采用开方乘十处理。
◇规范化:基于距离的挖掘算法,如最近邻分类,需要对数据进行标准化处理,也就是将其缩至特定的范围之内,如:[0,10]。如:对于一个顾客信息数据库中的年龄属性或工资属性,由于工资属性的取值比年龄属性的取值要大许多,如果不进行规格化处理,基于工资属性的距离计算值显然将远超过基于年龄属性的距离计算值,这就意味着工资属性的作用在整个数据对象的距离计算中被错误地放大了。规范化的方法有:
最小最大规范法: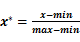
零-均值规范法: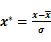
小数定标规范法: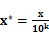
◇连续属性的离散化:一些算法,如决策树ID3算法、关联规则Aprior算法等,均要求数据是标称型数据,这就需要将数值型数据离散化为标称型数据。离散化的方法有等宽分箱法、等频分箱法、聚类分箱法。

例题:1:离散化数据
有如下12个数据5,10,13,15,11,55,50,35,92,72,204,215,请你用等宽分箱法、等频分箱法、聚类分箱法将上述数据分成三箱。
解析:排序后5,10,11,13,15,35,50,55,72,92,204,215
① 等宽分箱法
总宽度=215-5=210,分成三箱。宽度为70,故分点为5~75、76~146、147~217。
故,bin1={5,10,11,13,15,35,50,55,72}、bin2={92}、bin3={204、215}。
②等频分箱法
样本数据n=12,等频分为三箱,显然每一箱4个数。故bin1={5,10,11,13}、bin2={15,35,50,55}、bin3={72,92,204,215}。
③聚类分箱法
现实中区分事物常常采用距离的方法,距离近,表示彼此之间是一类,距离远,表示彼此之间不是一类。现在样本数据容量为12,分成三箱,需要找到数和数之间第一大的距离,和第二大的距离。即92和204之间的距离为112;35和55之间的距离为20,故bin1={5,10,11,13,15}、bin2={35,50,55,72,92}、bin3={204、215}。

(4)数据归约
数据归约的目的就是缩小所挖掘数据的规模,但却不会影响(或基本不影响)最终的挖掘结果。数据归约的策略有属性归约和数值归约。属性归约,也叫维归约,即通过删除不相关的属性(或维)减少数据量。具体方法有合并属性、逐步向前选择、逐步向后删除、决策树归纳、主成分分析等。







