
-
1 知识点回顾
-
2 练习题及解析
-
3 章节自测

某个数学家遇见多年未见的朋友。
朋友说:我的三个孩子都是今天的生日,你能算出他们的年龄吗?他们三个的年龄之积是36,年龄之和是那栋房子的窗户数。
数学家看过房子说:我还需要一点信息。
朋友说:我大儿子的眼睛是蓝色的。
数学家说:OK。我算出来了。
通过这个示例,我们讲解了传统思维模式求解问题的方法,与计算思维模式求解问题的方法。


传统思维模式 计算思维模式

算法是指解决问题的方法和步骤。
算法的要素主要有:
(1)基本操作:算术运算、关系运算、逻辑运算、数据传输。
(2)控制结构:顺序结构、选择结构、循环结构。
算法的特征是:
(1)有穷性:算法必须在有限个步骤内完成任务。
(2)确定性:算法的描述必须无歧义,以保证算法的实际执行结果是精确地符合要求或期望。
(3)可行性:又称有效性。能够实现,算法中描述的操作都是可以通过已经实现的基本运算执行有限次来实现。
(4)输入:一个算法必须有零个或以上输入量。
(5)输出:一个算法应有一个或以上输出量,输出量是算法计算的结果。
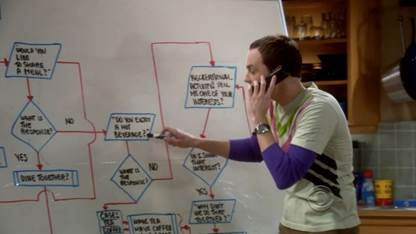
算法描述的方法:(1)自然语言 (2)流程图 (3)伪代码

变量:是指在程序的运行过程中,值可以变化的一段内存空间,也就是说,变量其实只不过是程序可操作的存储区的名称。变量的名称可以由字母、数字和下划线字符组成。它必须以字母或下划线开头(数字不能开头)。
常量:是固定值,在程序执行期间不会改变。如:数值常量、符号常量等。
运算符:用于执行程序代码运算,会针对一个以上操作数项目来进行运算。例如:2+3,其操作数是2和3,而运算符则是“+”。通常有赋值运算符、算术运算符、关系运算符和逻辑运算符。

表达式:由常量、变量、运算符组成的式子叫做表达式,例如:a+2,就是算数表达式。
赋值运算符:赋值运算符就是“=”,它的作用是将一个表达式的值赋给一个左值。
左值:指向内存位置的表达式被称为左值表达式。左值可以出现在赋值号的左边或右边。
右值:指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
右值可以是变量、常量、或表达式,左值只能是变量,不能是常量和表达式。
raptor软件中,赋值运算符可以用“=”表示,也可以用“←”表示。即将右值拷贝给左值。

(1)条件表达式
条件表达式是我们在程序中做一些判断时要用的句型,最常用的是比较两个数值的关系,其语法如下:数值一关系操作数 数值二
关系操作数有:
< 小于
> 大于
= 等于 (注意,是两个等号)
<= 小于或等于
>= 大于或等于
<> 或 != 不等于

(2)if语句
◇单分支语句
if 条件式 语句
上面的语法是如果符合该条件,则执行语句。上述语句是单行形式,也可以写成块状形式:
if 条件式 then
语句
end if
◇双分支语句
有时候我们在条件不成立的时候也必需执行一些指令,这时候可以改用下面的语法:
if 条件式 语句一 else 语句二
上面 else 后面的语句二就是当条件不成立时所要执行的语句。当然也可以写成块状形式。
if 条件式 then
语句一
else
语句二
endif
◇ 多分支语句
有时候我们要执行的语句并不只一行,而是语句组,例如:
if 条件式
语句一
语句二
…
语句n
else
语句n+1
指令n+2
…
语句m
endif
上面的语法,当条件成立时程序会执行语句一至n,而当条件不成立的时候则是执行语句n+1至语句m。
注意:多分支语句没有单行形式。

(1)while 的语法:
while 条件式 do 语句一
上面的语法是当条件式成立时,程序会重复执行语句一,每执行完语句一之后,便再检查一次该条件式是否成立,如果成立,则继续执行循环体内的语句(即语句一),而如果条件式不成立了,则离开这个循环,执行while循环后的语句。上面的语法,如果我们希望条件成立的时候能执行一堆指令(语句组),可以写成块状形式,如:
while 条件式 do
语句一
语句二
语句三
endwhile

(2)for语句
接下来我们来看for循环:
for 初值 to终值 [step n] 语句一;
或
for 初值 to终值 [step n]
语句一
语句二
…
语句n
endfor

所谓数组,是有序的元素序列。若将有限个类型相同的变量的集合命名,那么这个名称为数组名。组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量。用于区分数组的各个元素的数字编号称为下标。

比如 numbers是一个数组的化,那么numbers[1]、numbers[2]、...、numbers[100] 可以来代表数组中的某一个元素,也可以通过下标索引来访问数组元素。数组是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。

函数是一组一起执行一个任务的语句。函数还有很多叫法,比如方法、子例程或子程序等。
(1)函数的类型:
◇ 系统预定义(比如:三角函数、数学函数、字符串函数、…);
◇ 用户自定义函数
(2)函数注意事项
◇ 函数名:这是函数的实际名称。函数名代表函数的功能。
◇ 函数参数:参数是可选的,也就是说,函数可能不包含参数。
◇ 函数返回值:一个函数可以返回一个值。
(3)主调函数和被调函数
A,B两个函数。如果A函数调用了B函数,那么A叫做主调函数,B叫做被调函数。

(4)主调函数格式
变量 = 函数名(参数列表)
注:主调函数中的参数列表叫做实参,即实际参数,也就是说,具有实际的值。
(5)被调函数格式
function函数名(参数列表)
...
endfunction
注:被调函数中的参数列表叫做形参,即形式参数,也就是说,这只是形式上的参数,无论什么传过来什么值,都是这套做法。


在进行归纳推理时,如果逐个考察了某类事件的所有可能情况,因而得出一般结论,那么这结论是可靠的,这种归纳方法叫做枚举法。枚举法,也称穷举法、暴力法、蛮力法等,就是利用计算机运算速度快、精确度高的特点,对要解决问题的所有可能情况,一个不漏地进行检验,从中找出符合要求的答案,因此枚举法是通过牺牲时间来换取答案的全面性。
枚举法的设计要关注一下两个方面:
(1)确定枚举的范围
(2)找出约束的条件
在确定枚举对象、枚举范围和约束条件后,就可以枚举可能的解,进而验证是否是问题的解。枚举法可以通过循环+条件判断来实现,对应到伪代码就是for加if。
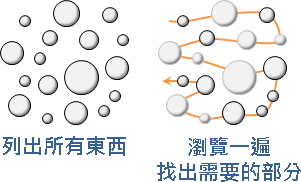

生活中的递归现象很多,比如德罗斯特效应、文字递归和分形图形等。
德罗斯特效应是递归的一种视觉形式,是指一张图片的某个部分与整张图片相同,如此产生无限循环(如下左图);从前有个山,山里有个庙,庙里有个老和尚在给小和尚讲故事,讲的是从前有个山,山里有个庙…,上述文字就是文字递归(如下中图);分形是具有以非整数维形式充填空间的形态特征。通常被定义为“一个粗糙或零碎的几何形状,可以分成数个部分,且每一部分都(至少近似地)是整体缩小后的形状”,即具有自相似的性质(如下右图)。



嵌套函数,就是指在某些情况下,您可能需要将某函数作为另一函数的参数使用,这一函数就是嵌套函数。例如cos(30*pi()/180)),这里cos函数里嵌套了一个pi函数,也就是说pi函数作为cos函数的参数。如果在调用一个函数的过程中又出现直接或间接地调用该函数本身,称为函数的递归调用。如:cos(cos(30*pi()/180))。这里cos函数里直接调用了一个cos函数,被称为递归调用。
递归算法的设计
(1)缩小规模:将原问题转换为性质相似的独立子问题
(2)递归出口:有递归终止的条件
递归算法的三要素
(1)递归式:即递归公式,或递归函数
(2)递归出口:即递归终止条件,类似循环中的初始条件。
(3)界函数:问题规模变化的函数,保证递归规模向出口靠拢,类似循环中的步长。
递归法的实现可以采用条件判断和函数调用。

从问题的规模(项数)出发,找到大规模问题与小规模问题之间的关系(或前后项之间的关联),然后根据他们之间的联系逐步求解。这种在规定的初始条件下,找出后项对前项的依赖关系的操作,称为递推。
表示某项和它前面若干项的关系式就叫递推公式。初始条件称为边界条件。
递推设计
(1)找出递推规律,写出递推公式
(2)根据初始条件,顺推或逆推。
递推实现可以用非递归法实现、也可以用递归法实现。

迭代法也称辗转法,是一种不断用变量的旧值递推新值的过程,跟迭代法相对应的是直接法(或者称为一次解法),即一次性解决问题。迭代算法是用计算机解决问题的一种基本方法,它利用计算机运算速度快、适合做重复性操作的特点,让计算机对一组指令(或一定步骤)进行重复执行,在每次执行这组指令(或这些步骤)时,都从变量的原值推出它的一个新值,迭代法又分为精确迭代和近似迭代。


分治法,分割问题、各个击破。将一个大问题,分割成许多小问题。如果小问题还是很难,就继续分割成更小的问题,直到问题变得容易解决。分割出来的小问题,称作「子问题」。解决一个问题,等价于解决所有子问题。用树形图表达原问题与子问题的关系,最好不过!
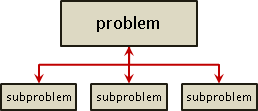
分治法着重分割问题的方式── 要怎么分割问题,使得子问题简单又好算?
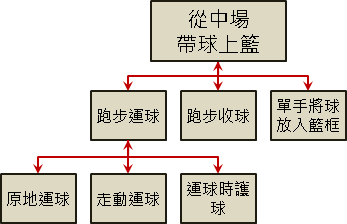
示例:分解动作
想要学习「从中场带球上篮」,我们可以将此动作分割为「跑步运球」、「跑步收球」、「单手将球放入篮框」等动作,分别学习。每一项动作都熟练之后,组合起来便是带球上篮了。如果觉得「跑步运球」还是太难,可以更细分成「原地运球」、「走动运球」、「运球时护球」等动作,克服了之后便能够顺利解决「跑步运球」的问题了。

多阶段决策过程,是指这样一类的决策问题:由问题的特性,可将过程按时间、空间等标志分为若干个互相联系又相互区别的阶段,在它的每一个阶段都需要做出决策,从而使整个过程达到最好的效果。
(1)什么是动态规划?
20世纪50年代,美国数学家Bellman在研究多阶段决策过程的优化问题时,提出了著名的最优化原理。这种优化理论,把多阶段过程转化为一系列单阶段问题,利用各阶段之间的关系,逐个求解,从而创立了解决这类过程优化问题的新方法——动态规划。
(2)动态规划的特点
◇ 决策者需要作出时间上有先后之别的多次决策。
◇ 前一次决策的选择将直接影响到后一次决策,后一次决策的状态取决于前一次决策的结果。
◇ 决策者关心的是多次决策的最终结果,而不是各决策的即时结果。

(3)基本概念
◇阶段:把一个复杂的决策问题按时间或空间特征分解为若干个相互联系的阶段,以便顺序求解。一般用 k 表示。阶段是对整个过程的自然划分。
◇状态:每个阶段有若干个状态,表示某一个阶段决策面临的条件或所处的位置。一般用 s 表示。
◇决策:就是关于状态的选择,是决策者从给定阶段状态触发对下一阶段状态作出的选择。一般用Xk=XK(SK)表示。表示k阶段,状态Sk时的决策。
◇状态转移方程:一个状态到另一个状态的转移过程由状态转移过程描述。大多数情况下可以用数学公式表达。
◇ 指标函数:分为阶段函数和过程函数(目标函数)两种。它是全过程或子过程或各阶段上确定数量的函数。如费用、成本、距离、利润、时间等。
◇ 最优解:对指标函数求解,称为最优解。
(4)动态规划步骤
划分阶段à选择状态à确定决策à写出状态转移方程à确定决策变量取值范围(包括边界条件)à写出指标函数递推公式à逆序求解。
(5)适用条件
◇最优化子结构:一个最优化策略的子策略总是最优的。一个问题满足最优化原理又称其具有最优子结构性质。
◇无后效性:每个状态都是过去历史的一个完整总结。
◇重叠子问题:子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。
(6)动态规划的优缺点
优点:解决复杂问题、找到全局最优解、可以得到一组解。
缺点:依赖于经验和技巧、无后效性局限大、维数灾难。

(7)动态规划算法框架
input 阶段变量,状态变量,决策变量,状态数组
for i = 阶段最大值 downto 1 step -1 // 倒推每一个阶段
for j = 状态最小值 to 状态最大值 // 枚举阶段i的每一个状态
for k = 决策最小值 to 决策最大值 // 枚举 i 阶段 j 状态下的每一种决策
目标函数
output 最优方案

贪心算法,也称贪婪法。顾名思义,是指在求解最优化问题时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,所做出的仅是在某种意义上的局部最优解,或者是整体最优解的近似解。
(1)基本要素
◇贪心选择:是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素。
◇最优子结构:当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。运用贪心策略在每一次转化时都取得了最优解。问题的最优子结构性质是该问题可用贪心算法或动态规划算法求解的关键特征。

(2)步骤
①根据题意选取一种度量标准
②按照这种度量标准对数据进行排序
③循环+判断,保留可行解,舍去无效解

(1)概念
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
(2)基本思想
在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根结点出发深度探索解空间树。当探索到某一结点时,要先判断该结点是否包含问题的解,如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则逐层向其祖先结点回溯。(其实回溯法就是对隐式图的深度优先搜索算法)。
若用回溯法求问题的所有解时,要回溯到根,且根结点的所有可行的子树都要已被搜索遍才结束。而若使用回溯法求任一个解时,只要搜索到问题的一个解就可以结束。

(3)回溯算法的步骤
①针对所给问题,定义问题的解空间
②确定解空间树
③深度优先方式搜索解空间树

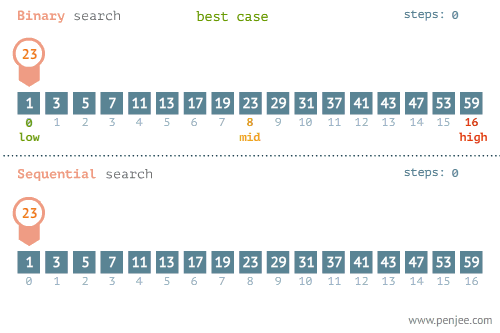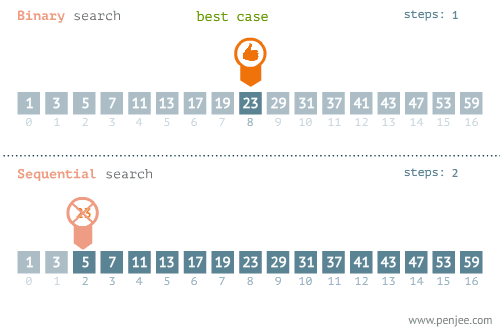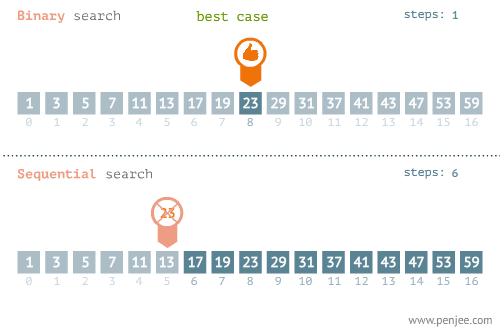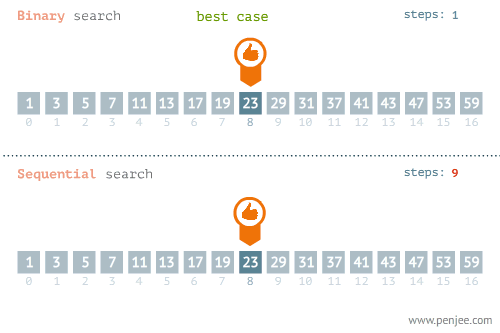
顺序查找是人们最熟悉的查找策略,对于小规模的数据,顺序查找是个不错的选择。顺序查找的方法是从数据的第一个元素开始,依次比较,直到找到目标数据或查找失败。算法最好情况是第一个元素就是目标数据,最糟糕的情况是最后一个元素才是目标的数据。顺序查找平均关键字匹配次数为表长的一半。
顺序查找的步骤
(1)从表中的第一个元素开始,依次与关键字比较。
(2)若某个元素匹配关键字,则查找成功,并退出查找。
(3)若查找到最后一个元素还未匹配关键字,则查找失败。

折半查找,也称二分查找,是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。正因为如此,折半查找效率较高。
折半查找法的优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。

(1)选择排序
选择排序是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
(2)冒泡排序
冒泡排序的思想是重复地走访过要排序的元素列,依次比较两个相邻的元素,如果它们的顺序(如从大到小、首字母从A到Z)错误就把它们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。这个算法的名字由来是因为大数沉底、小数上浮,就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
(3)插入排序
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。


