
上课日期:第八周 2020.10.29 5-6节,西校区工程中心204
出勤统计:应到41/实到39/迟到0/请假0/旷课2(陈烨爵、丁添一)
通过前面课程的学习,我们已经知道,由人工智能所设计的智能体,已经可以像人类一下,不仅在确定性任务环境中具备“搜索”的能力,以及在“不确定任务环境”中具备“目标优化”的能力,甚至包括还包括在部分可观察环境中具备“推理”能力。
本讲我们重点介绍“强化学习”,相比我们之前介绍的所有内容,“强化学习”可以帮助智能体适应未知任务环境。通过“强化学习”,智能体可以如同人类和动物一样,在未知任务环境中,能够实现探索(Exploration)和开发(Exploitation)。所谓探索,就是在环境中获取更多信息;所谓开发,就是利用已有的信息获取最大回报。探索和开发的能力,是通过学习完成的。广义的学习是指人与动物在生活过程中凭借经验产生的行为、或行为潜能的相对持久的变化。如下图所示,我们人类和动物的学习过程包括两个部分,分别为模仿和总结。正是两个部分的不停交替重复,才使得人和动物通过学习,掌握了众多技能。

在人工智能范畴内,我们讨论机器学习。通常,机器学习分为监督学习、非监督学习和强化学习,其中,强化学习是本次课程所要介绍的重点。作为介入监督学习和非监督学习之间的一种学习方式,强化学习具有以下特点:
第一、在强化学习中,外部环境不会告诉智能体程序应该采取什么样的动作,只会反馈采取的动作是好、还是坏。
第二、智能体程序得到的奖励并不是即时的。比如,在下围棋中,你可能在很多步之后才会知道这个动作是好的动作,还是坏的动作。
第三、在监督学习中,假设数据是独立同分布的,预测数据和训练数据的分布是一致的。但在强化学习中,这个基本的假设是不成立的,因为智能体会通过执行动作,实现与环境的交互,导致其从环境中获取的数据分布会不断发生改变。
根据以上介绍的特点,我们可以发现,强化学习是一种“没有指导、只有评论”的新型学习方式,就如同导师在指导研究生,导师并不给出具体的研究指导,只对研究生的研究结果进行评论。强化学习有广泛的应用场景,比如像直升机特技飞行训练,投资管理,发电站控制,让机器人模仿人类行走等。
下面,我们通过“倒立摆控制系统”设计案例,来感受机器学习中的强化学习。“倒立摆控制系统”是一个复杂的、不稳定的、非线性系统。通常,它可以作为进行控制算法验证的理想实验平台。例如,通过对倒立摆的控制,可以较好检验新的控制方法是否有较强的,处理非线性和不稳定性问题的能力。如下图所示的倒立摆,它包含两个铰链,一个与小车相连,一个为两个连杆的交汇处。输入为小车的力,输出为小车的位置,铰链的速度、角速度和角加速度;这些变量之间的关系,可以通过倒立摆的动力学方程来表示。

通过强化学习,智能体程序可以学习在任意时刻t,应该施加给小车的力的方向和大小。强化学习是智能体在环境给予的奖励的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。以控制对象的动力学方程建立物理引擎,作为其环境交互对象,并定义其奖励,使智能体获取的奖励最大化,最终达到控制目的。
在结束本次课程之前,我们对强化学习智能体程序的主要组成部分进行介绍。
第一、强化学习中的策略 Policy
策略是决定个体行为的机制。是从状态到行为的一个映射,可以是确定性的,也可以是不确定性的。
第二、强化学习中的价值函数 Value Function
价值函数是对未来奖励的预测,用来评价当前状态的好坏程度。当面对两个不同的状态时,个体可以用一个Value值来评估这两个状态可能获得的最终奖励区别,继而指导选择不同的行为,即制定不同的策略。同时,一个价值函数是基于某一个特定策略的,不同的策略下同一状态的价值并不相同。某一策略下的价值函数可用以下公式进行表示:
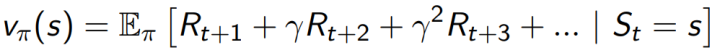
第三、模型 Model
个体对环境的一个建模,体现了个体是如何思考环境的运行机制,也就是个体希望模型能模拟环境与个体的交互机制。任何模型至少要解决两个问题:一是状态转化概率,即预测下一个可能状态发生的概率;模型的另一项工作是预测可能获得的即时奖励。值得一提的是,模型并不是构建一个智能体所必需的,很多强化学习算法中个体并不试图(依赖)构建一个模型。
最后,请同学们区分“学习任务”和“规划规划”这两个不同的概念。在学习任务,环境初始时是未知的,个体不知道环境如何工作,个体通过与环境进行交互,逐渐改善其行为策略。在规划任务中,环境如何工作对于个体是已知,或者近似已知的,个体并不与环境发生实际的交互,而是利用其构建的模型进行计算,在此基础上改善其行为策略。

