
一 读取这个网页的内容 urlopen().read()
from urllib.request import urlopen
print(urlopen('http://www.baidu.com').read())

按照读字节的方式,获取了网页的全部内容并显示
二 读取这个网页的内容 从urlopen()列表中,一行一行读取
from urllib.request import urlopen
for line in urlopen('http://www.baidu.com'):
print(line)
break

按行读取。只读了一行
三 增加了解码 decode()
from urllib.request import urlopen
for line in urlopen('http://www.baidu.com'):
print(line.decode('utf-8')) #Decoding the binary data to text.
break
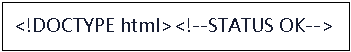
通过decode() 解码,按 utf-8 解码
四 读网页
from urllib.request import urlopen
response=urlopen('http://www.baidu.com')
print(response.read())
五 最常用的几个函数
response.read()
response.read(5) # 只读取5个字节
response.readline() # 按行读取,读取当前行
response.readlines() # 按行读取,获得全部行,形成一个列表
response.getcode() # 获取状态码,比如:200、404
response.geturl() # 获取url
response.getheaders() # 获取网页的<head></head>

