
jieba库,切词
上一节
下一节
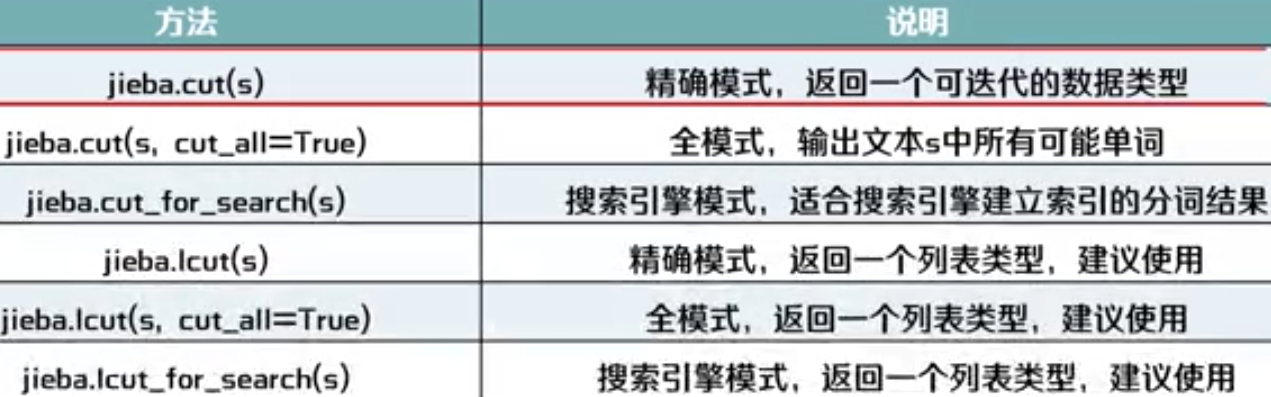
注:lcut的含义是 list cut,结果直接转化为列表
例1:lcut( )
import jieba
s='央视曝长租公寓高收低租卷款跑路'
print(jieba.lcut(s))

从结果看:
‘曝长’这个词,断得不对。
“跑”“路”不应该分开。可以把"跑路"这个词,添加到自己电脑的 jieba 库。
例2:lcut(s , cut_all=True) —— 尽可能细分
import jieba
s='央视曝长租公寓高收低租卷款跑路'
print(jieba.lcut(s,cut_all=True)))
从结果看,把‘长’、‘租’分开,‘低’、‘租’分开还有‘卷款’、‘跑路’分开,也不合适
例3:lcut 的 3 种函数的用法比较
from jieba import *
s='1949年10月1日, 中华人民共和国正式成立'
print(lcut(s))
print(lcut(s,cut_all=True))
print(lcut_for_search(s))
['1949', '年', '10', '月', '1', '日', ',', ' ', '中华人民共和国', '正式', '成立']
['1949', '年', '10', '月', '1', '日', ',', ' ', '', '中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国', '正式', '成立']
['1949', '年', '10', '月', '1', '日', ',', ' ', '中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '正式', '成立']

