9.2.2无损编码方法
1.霍夫曼编码
霍夫曼编码(Huffman)是运用信息熵原理的一种无损编码方法,这种编码方法根据源数据各信号发生的概率进行编码。
在源数据中出现概率大的信号,分配的码字越短;出现概率越小的信号,其码字越长,从而达到用尽可能少的码表示源数据。
1.1霍夫曼编码的算法
(1).初始化,根据符号概率的大小顺序对符号进行排序。
(2).把概率最小的两个符号组成一个新符号(节点),即新符号的概率等于这两个符号概率之和。
(3).重复第2步,直到形成一个符号为止(树),其概率和等于1。
(4).分配码字。码字分配从最后一步开始反向进行,即从最后两个概率开始逐渐向前进行编码,对于每次相加的两个概率,给概率大的赋“0”,概率小的赋“1”(也可以全部相反,如果两个概率相等,则从中任选一个赋“0”,另一个赋“1”)。
1.2 霍夫曼编码的特点
霍夫曼编码构造出来的编码值不是唯一的。
对不同信号源的编码效率不同
由于编码长度可变,因此译码时间较长;编码长度的不统一,也使得硬件实现有难度。
2.行程编码
行程编码又称行程长度编码(Run Length Encoding,RLE),是一种熵编码。这种编码方法广泛地应用于各种图像格式的数据压缩处理中。
行程编码的原理是在给定的图像数据中寻找连续重复的数值,然后用两个字符取代这些连续值。即将具有相同值的连续串用其串长和一个代表值来代替,该连续串就称为行程,串长称为行程长度。
如图所示,假定一幅灰度图像,第n行的像素值为:
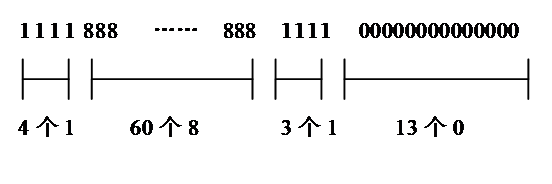
用RLE编码方法得到的代码为:4160831130。代码斜黑体表示的数字是行程长度,黑体字后面的数字代表像素的颜色值。例如黑体字60代表有连续60个像素具有相同的颜色值,它的颜色值是8。
对比RLE编码前后的代码数可以发现,在编码前要用80个代码表示这一行的数据,而编码后只要用10个代码表示代表原来的80个代码,压缩前后的数据量之比约为8:1,即压缩比为8:1。
2.1 行程编码的分类
定长编码
定长编码是指编码的行程长度所用的二进制位数固定
不定长编码
变长行程编码是指对不同范围的行程长度使用不同位数的二进制位数进行编码。使用变长行程编码需要增加标志位来表明所使用的二进制位数。
3.词典编码
词典编码(dictionary encoding)技术属于无损压缩技术,主要是利用数据本身包含许多重复的字符串的特性。可以用一些简单的代号代替这些字符串,就可以实现压缩,实际上就是利用了信源符号之间的相关性。字符串与代号的对应表就是词典。词典编码法的种类有很多,归纳起来大致有两种。
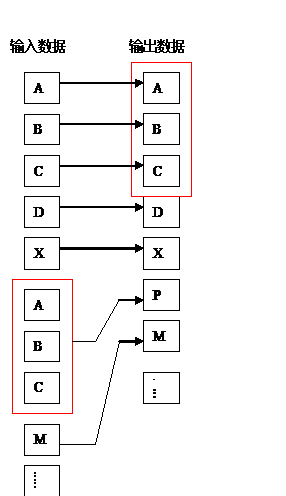
第一种方法的思想是查找目前正在压缩的字符序列在以前输入的数据中是否出现过,然后用出现过的字符串代替重复的部分,它的输出仅仅是指向早期出现过的字符串“指针”。
这种编码的概念如右图所示。这里所指的词典是指用以前处理过的数据表示编码过程中遇到的重复部分。这类编码的所有算法都是以LZ77算法为基础的。
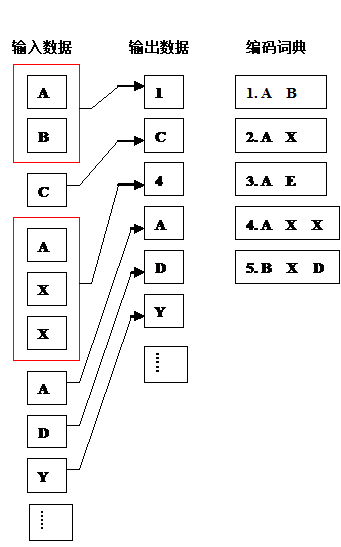
第二种算法的思想是从输入的数据中创建一个“短语词典”,这类短语不一定有具体的含义,可以是任意字符的组合。在编码过程中遇到在“短语词典”中出现的短语是,编码器就输出这个词典中的短语“索引号”,而不是短语本身。其概念如右图所示。
3.1词典编码-LZ77算法
LZ77是以以色列计算机专家Abraham Lempel和Jakob Ziv在1977年开发和发表的。
此算法的一个改进算法是由Storer和Szymanski在1982年开发的,称为LZSS算法。
LZ77 算法在某种意义上又可以称为“滑动窗口压缩”,该算法将一个虚拟的、可以跟随压缩进程滑动的窗口作为词典,要压缩的字符串如果在该窗口中出现,则输出其出现位置和长度。
3.1.1词典编码-LZ77算法中的概念
输入字符流(input stream):要被压缩的字符序列。
字符(character):输入数据流中的基本单元。
编码位置(coding position):输入数据流中当前要编码的字符位置,指前向缓冲存储器中的开始字符。
前向缓冲存储器(Lookahead buffer):存放从编码位置到输入数据流结束的字符序列的存储器。
窗口(window):指包含W个字符的窗口,字符是从编码位置开始向后数也就是最后处理的字符数。
指针(pointer):指向窗口中的匹配串且含长度的指针。
3.1.2词典编码-LZ77算法步骤
把编码位置设置到输入数据流的开始位置。
找窗口中最长的匹配串
以“(Pointer, Length) Characters”的格式输出,其中Pointer是指向窗口中匹配串的指针,Length表示匹配字符的长度,Characters是前向缓冲存储器中的不匹配的第1个符。
如果前向缓冲存储器不是空的,则把编码位置和窗口向前移(Length+1)个字符,然后返回到步骤(2)。
3.2词典编码-LZW算法
LZW压缩算法是一种新颖的压缩方法,它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩文件只存贮数字,则不存贮串,从而使图像文件的压缩效率得到较大的提高。
LZW编码是围绕称为词典的转换表来完成的。
3.2.1词典编码-LZW相关概念
前缀(Prefix): 在一个字符之前的字符序列。
缀-符串(String):前缀+字符。
码字(Code word):码字流中的基本数据单元,代表词典中的一串字符。
码字流(Codestream): 码字和字符组成的序列,是编码器的输出。
词典(Dictionary): 缀-符串表。按照词典中的索引号对每条缀-符串(String)指定一个码字(Code word)。
当前前缀(Current prefix):在编码算法中使用,指当前正在处理的前缀,用符号P表示。
当前字符(Current character):在编码算法中使用,指当前前缀之后的字符,用符号C表示。
当前码字(Current code word): 在译码算法中使用,指当前处理的码字,用W表示当前码字,String.W表示当前码字的缀-符串。
3.2.2词典编码-LZW算法执行步骤
开始时的词典包含所有可能的根(Root),而当前前缀P是空的;
当前字符(C) :=字符流中的下一个字符;
判断缀-符串P+C是否在词典中
如果“是”:P := P+C // (用C扩展P) ;
如果“否”:① 把代表当前前缀P的码字输出到码字流;② 把缀-符串P+C添加到词典;③ 令P := C //(现在的P仅包含一个字符C);
判断字符流中是否还有字符要编码
如果“是”,就返回到步骤2;
如果“否”:① 把代表当前前缀P的码字输出到码字流;② 结束。

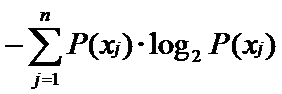
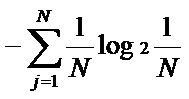 =
=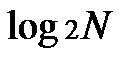
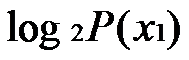 =0
=0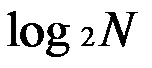
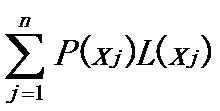 (j=1,2,…,n)
(j=1,2,…,n)