(1)了解数字媒体数据压缩的原因
(2)理解数字媒体数据压缩技术的不同分类
(3)掌握通用的数据压缩编码算法,如霍夫曼编码、词典编码、PCM、DM算法
(4)了解各种数字媒体数据压缩的标准
9.1.1媒体数据压缩的原因与必要性
数字媒体包括了文本、数据、声音、动画、图形、图像以及视频等多种媒体信息。经过数字化处理后其数据量是非常大的,如果不进行数据压缩,计算机系统就难以对它进行存储、交换和传输。
9.1.2压缩的可能性与信息冗余
数据能够被压缩的主要原因在于媒体数据中存在数据的信息冗余。信息量包含在数据之中,一般的数据冗余主要体现在:
(1)空间冗余
一幅图像中,都会有由许多灰度或颜色都相同的或者邻近像素组成的区域,它们就形成了一个性质相同的集合块,这样在图像中就表现为空间冗余。对空间冗余的压缩方法就是把这种集合块当作一个整体,用极少的信息来表示它,从而节省存储空间。
(2)结构冗余
有些图像的有很强的纹理区或者分布模式,就会造成结构冗余,这样就可以根据已知图像的分布模式,可以通过某一过程生成图像。
(3)时间冗余
在序列图像(电视图像、运动图像)或者音频的表示中经常包含时间冗余。比如图像系列中,相邻的图像具有很大的相似性;
(4)视觉冗余
由于人类的视觉系统并不能对图像画面的任何变化都能很准确的做出判断,视觉系统对于图像的注意更是非均匀和非线性的,即主要部分的图像质量,取画面的整体效果,不拘泥于细节。
(5)知识冗余
有些多媒体信息的理解与我们大脑中间已有的某些知识有相当大的相关性。例如:鹰的图像有固有的结构,比如,鹰有两只翅膀,头部有眼、鼻、耳朵,有尾巴等。这类规律性的结构可由先验知识和背景知识得到称为知识冗余。
(6)信息熵冗余
冗余度表示了由于每种字符出现的概率不同而使信息熵减少的程度。显然,由于信息熵的减少,为了表示相同的内容,相同的信息量,文章的字符数要多一点,这就是文章的冗余性。从而信息熵的冗余也会造成信息量的加大。
9.1.3数据压缩的分类
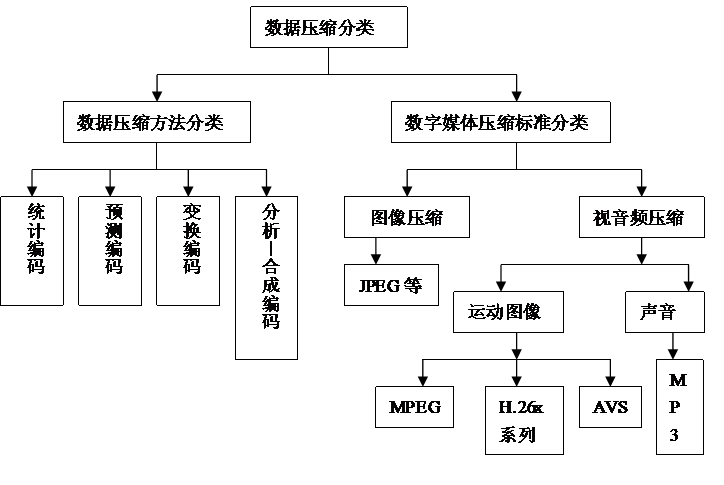
按信息压缩前后比较是否有损失,可以划分有损压缩和无损压缩 :
无损压缩指使用压缩后的数据进行重构,重构后的数据与原来的数据完全相同。常用的无损压缩算法有霍夫曼(Huffman)算法和LZW算法 。
有损压缩是指使用压缩后的数据进行重构,重构后的数据与原来的数据有所不同,但不影响人对原始资料表达的信息造成误解。
按数据压缩编码的原理和方法可划分为:
统计编码,主要针对无记忆信源,根据信息码字出现概率的分布特征而进行压缩编码,寻找概率与码字长度间的最优匹配。
预测编码是利用空间中相邻数据的相关性来进行压缩数据的。
变换编码是将图像时域信号转换为频域信号进行处理。
分析—合成编码是指通过对源数据的分析,将其分解成一系列更适合于表示的“基元”或从中提取若干更为本质意义的参数,编码仅对这些基本单元或特征参数进行。
按照媒体的类型进行压缩划分:
图像压缩标准
声音压缩标准
运动图象压缩标准


