
【扩充知识】机器学习——关联规则——支持度(support)、置信度(confidence)、提升度(Lift)
上一节
下一节
一、支持度、置信度和提升度
![]()
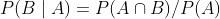
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
通过分析超市的购物篮,如果我们发现商品X和Y被顾客同时购买的频率很高,那么就可以做如下操作:
把购买商品Y的顾客视为商品X的广告宣传对象;
把商品X和Y摆放在同一个货架上,以刺激购买其中一款商品的顾客同时购买另一款商品;
把商品X和Y合并成一款新商品,比如具有Y口味的X。
关联规则可用于揭示商品之间的关联信息,从而增加销售利润。不仅如此,关联规则还可以用于其他领域。比如,在医疗诊断中,了解共病症状有助于改善治疗效果。
一般我们使用三个指标来度量一个关联规则,这三个指标分别是:支持度、置信度和提升度。
Support(支持度):表示某个项集出现的频率,也就是包含该项集的交易数与总交易数的比例。例如P(A)表示项集A的比例,
表示项集A和项集B同时出现的比例。
Confidence(置信度):表示当A项出现时B项同时出现的频率,记作{A→B}。换言之,置信度指同时包含A项和B项的交易数与包含A项的交易数之比。公式表达:{A→B}的置信度为
Lift(提升度):指A项和B项一同出现的频率,但同时要考虑这两项各自出现的频率。公式表达:{A→B}的提升度={A→B}的置信度/P(B)
提升度反映了关联规则中的A与B的相关性,提升度>1且越高表明正相关性越高,提升度<1且越低表明负相关性越高,提升度=1表明没有相关性。负值,商品之间具有相互排斥的作用。
案例1:
有以下一份购物交易记录:
表格中一条记录代表一条购物交易记录,在这里我们明确几个定义:
事务:每一条交易称为一个事务,例如:上表中包含8个事务。
项:交易中的每一个物品称为一个项,例如:苹果、啤酒。
项集:包含零个或者多个项的集合叫做项集,例如{苹果,啤酒} 、{牛奶,啤酒,米饭}。
k-项集:包含k个项的项集叫做k-项集。例如{苹果}叫做1-项集,{牛奶,啤酒,米饭}叫做3-项集。
前件和后件:对于规则{苹果}->{啤酒},{苹果}叫前件,{啤酒}叫后件。
接下来我们来介绍度量关联规则的三个指标(支持度、置信度和提升度):
支持度:{苹果}在8次交易中出现了4次,所以其支持度为50%。一个项集也可以包含多项,比如{苹果,啤酒,米饭}的支持度为2/8,即25%。可以人为设定一个支持度阈值,当某个项集的支持度高于这个阈值时,我们就把它称为频繁项集。
置信度:{苹果→啤酒}的置信度=(支持度{苹果,啤酒}/支持度{苹果})=3/4,即75%。置信度有一个缺点,那就是它可能会错估某个关联规则的重要性。只考虑了苹果的购买频率,而并未考虑啤酒的购买频率。如果啤酒也很受欢迎(支持度很高),如上表,那么包含苹果的交易显然很有可能也包含啤酒,这会抬高置信度指标。关于置信度的局限,我们会在后面的篇幅继续讨论。
提升度:{苹果→啤酒}的提升度等于{苹果→啤酒}的置信度除以{啤酒}的支持度,
,{苹果→啤酒}的提升度等于1,这表示苹果和啤酒无关联。{X→Y}的提升度大于1,这表示如果顾客购买了商品X,那么可能也会购买商品Y;而提升度小于1则表示如果顾客购买了商品X,那么不太可能再购买商品Y。
案例2:置信度的局限——错估某个关联规则的重要性。
表1 与啤酒相关的3个关联规则
表2 各商品在与啤酒相关的关联规则中的支持度
{啤酒→汽水}规则的置信度最高,为17.8%。然而,在所有交易中,二者出现的频率都很高(如表2所示),所以它们之间的关联可能只是巧合。这一点可以通过其提升度为1得到印证,即购买啤酒和购买汽水这两个行为之间并不存在关联。
另一方面,{啤酒→男士护肤品}规则的置信度低,这是因为男士护肤品的总购买量不大。尽管如此,如果一位顾客买了男士护肤品,那么很有可能也会买啤酒,这一点可以从较高的提升度(2.6)推断出来。{啤酒→浆果}的情况则恰好相反。从提升度小于1这一点,我们可以得出结论:如果一位顾客购买了啤酒,那么可能不会买浆果。
虽然很容易算出各个商品组合的销售频率,但是商家往往更感兴趣的是所有的热销商品组合。为此,需要先为每种可能的商品组合计算支持度,然后找到支持度高于指定阈值的商品组合。
案例3:提升度和零事务的关系
10000个超市订单(10000个事务),其中购买三元牛奶(A事务)的6000个,购买伊利牛奶(B事务)的7500个,4000个同时包含两者。
那么通过上面支持度的计算方法我们可以计算出:
三元牛奶(A事务)和伊利牛奶(B事务)的支持度为:
三元牛奶(A事务)对伊利牛奶(B事务)的置信度为:包含A的事务中同时包含B的占包含A的事务比例。4000/6000=0.67,说明在购买三元牛奶后,有0.67的用户去购买伊利牛奶。
伊利牛奶(B事务)对三元牛奶(A事务)的置信度为:包含B的事务中同时包含A的占包含B的事务比例。4000/7500=0.53,说明在购买伊利牛奶后,有0.53的用户去购买三元牛奶。
在没有任何条件下,B事务的出现的比例是0.75,而出现A事务,且同时出现B事务的比例是0.67,也就是说设置了A事务出现这个条件,B事务出现的比例反而降低了。这说明A事务和B事务是排斥的。
下面就有了提升度的概念。
我们把0.67/0.75的比值作为提升度,即P(B|A)/P(B),称之为A条件对B事务的提升度,即有A作为前提,对B出现的概率有什么样的影响,如果提升度=1说明A和B没有任何关联,如果<1,说明A事务和B事务是排斥的,>1,我们认为A和B是有关联的,但是在具体的应用之中,我们认为提升度>3才算作值得认可的关联。
提升度是一种很简单的判断关联关系的手段,但是在实际应用过程中受零事务的影响比较大,零事务在上面例子中可以理解为既没有购买三元牛奶也没有购买伊利牛奶的订单。数值为10000-4000-2000-3500=500,可见在本例中,零事务非常小,但是在现实情况中,零事务是很大的。在本例中如果保持其他数据不变,把10000个事务改成1000000个事务,那么计算出的提升度就会明显增大,此时的零事务很大(1000000-4000-2000-3500),可见提升度是与零事务有关的,零事务越多,提升度越高。
将事务改成1000000个:
Support(支持度):
Confidence(置信度):
Lift(提升度):
零事务:1000000-4000-2000-3500=990500,可见零事务的个数提升之后,提升度越高。
二、先验原则
即使只有10种商品,待检查的总组合数也将高达1023(即210-1)。如果有几百种商品,那么这个数字将呈指数增长。显然,我们需要一种更高效的方法。
要想减少需要考虑的项集组合的个数,一种方法是利用先验原则。简单地说,先验原则是指,如果某个项集出现得不频繁,那么包含它的任何更大的项集必定也出现得不频繁。这就是说,如果{啤酒}是非频繁项集,那么{啤酒,比萨}也必定是非频繁项集。因此,在整理频繁项集列表时,既不需要考虑{啤酒,比萨},也不需要考虑其他任何包含啤酒的项集。
遵循如下步骤,可以利用先验原则得到频繁项集列表。
步骤1:列出只包含一个元素的项集,比如{苹果}和{梨}。
步骤2:计算每个项集的支持度,保留那些满足最小支持度阈值条件的项集,淘汰不满足的项集。
步骤3:向候选项集(淘汰步骤2不满足的项集后的结果)中增加一个元素,并利用在步骤2中保留下来的项集产生所有可能的组合。
步骤4:重复步骤2和步骤3,为越来越大的项集确定支持度,直到没有待检查的新项集。
下图描绘了利用先验原则对候选项集进行大幅精简的过程。如果{苹果}的支持度很低,那么它及其他所有包含它的候选项集都会被移除。这样一来,待检查项集的数量就减少了一大半。
除了识别具有高支持度的项集之外,先验原则还能识别具有高置信度或高提升度的关联规则。一旦识别出具有高支持度的项集,寻找关联规则就不会那么费劲了,这是因为置信度和提升度都是基于支持度计算出来的。
举个例子,假设我们的任务是找到具有高置信度的关联规则。如果{啤酒,薯片→苹果}规则的置信度很低,那么所有包含相同元素并且箭头右侧有苹果的规则都有很低的置信度,包括{啤酒→苹果,薯片}和{薯片→苹果,啤酒}。如前所述,根据先验原则,这些置信度较低的规则会被移除。这样一来,待检查的候选规则就更少了。
三、局限性
计算成本高:尽管利用先验原则可以减少候选项集的个数,但是当库存量很大或者支持度阈值很低时,候选项集仍然会很多。一个解决办法是,使用高级数据结构对候选项集进行更高效的分类,从而减少比较的次数。
假关联:当元素的数量很大时,偶尔会出现假关联。为了确保所发现的关联规则具有普遍性,应该对它们进行验证(详见机器学习的交叉验证)。
尽管有上述局限性,但在从中等规模的数据集中识别模式时,关联规则仍然是一个很直观的方法。

