
FP-growth树
上一节
下一节
FP-growth树
请各位同学学习参考教材的第6章!!!!!
各位宝贝同学可以结合课程内容在线学习!!!
一、FP-growth算法框架
FP-growth算法的基本思路如下:
①扫描一次事务数据库,找出频繁1-项集合,记为L,并把它们按支持度计数的降序进行排列。
②基于L,再扫描一次事务数据库,构造表示事务数据库中项集关联的FP树。
③在FP树上递归地找出所有频繁项集。
④最后在所有频繁项集中产生强关联规则。
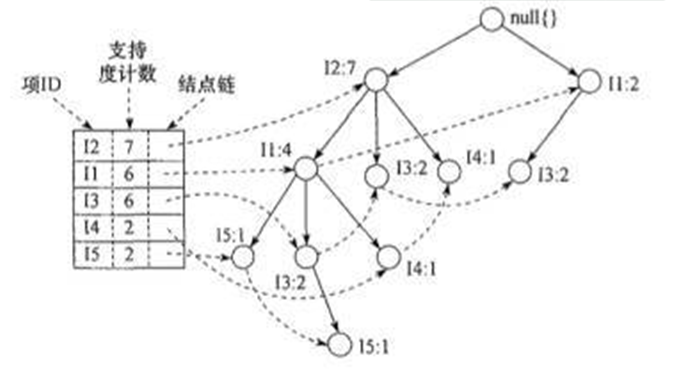
二、FP树构造
FP树是事务集合中项集关联的压缩表示,其构造方法如下:
①扫描一次事务数据库,找出频繁1-项集合L,并按支持度计数降序排序L中的频繁项。
②创建FP树的根结点,用“null”标记。
③再扫描一次事务集合,对每个事务找出其中的频繁项并按L中的顺序排序,为每个事务创建一个分支,事务分支路径上的结点就是该事务中的已排序频繁项。对于各个事务分支,如果可以共享路径则必须共享,并且在各个结点上记录共享事务数目;若不能共享则需要建立相应的子结点。
为了方便遍历FP树,为FP树创建一个项头表,项头表中每一行表示一个1-频繁项,并有一个指针指向它在FP树中的结点。
FP树中所有相同频繁项的结点通过指针连成一个链表。
从FP树可以看出,包含某个1-频繁项的所有可能的频繁项集可以通过这个链表搜索到。
三、由FP树产生频繁项集
由FP树产生频繁项集的过程是:由每个长度为1的频繁模式(初始后缀模式)开始,构造它的条件模式基,条件模式基由FP树中与后缀模式一起出现的前缀路径集组成。然后构造它的(条件)FP树,并递归地在该树上进行挖掘。
从上向下的路径构成模式{i1,i2,i3},{i3}称为它的后缀模式,对于后缀模式α,{i2}∪α称为增长后缀模式。{i1,i2}称为i3的前缀路径。

