
什么是数据挖掘?
一、数据挖掘的定义
1、定义
从技术角度看,数据挖掘(Data Mining,简称DM)是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们所不知道的、但又是潜在有用的信息和知识的过程。
从商业应用角度看,数据挖掘是一种崭新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转化、分析和模式化处理,从中提取辅助商业决策的关键知识。
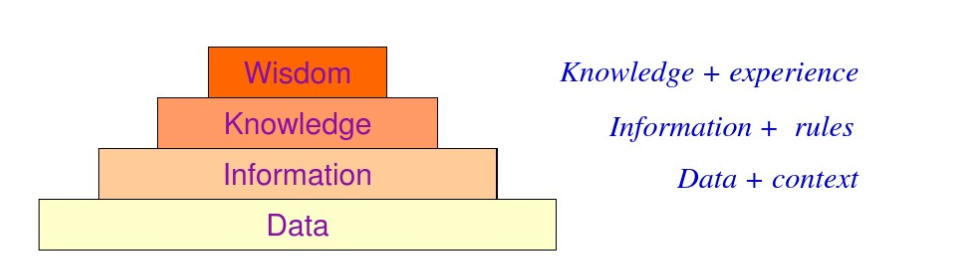
2、特点
(1)处理的数据规模身份庞大,达到GB、TB数量级,甚至更大;
(2)其目标是寻找决策者可能感兴趣的规则或模式;
(3)发现的知识要可接受、可理解、可运用;
(4)在数据挖掘中,规则的发现是基于统计规律的。
(5)数据挖掘所发现的规则是动态的,它只反映了当前状态的数据库具有的规则,随着不断向数据库加入新数据,需要随时对其进行更新。
二、数据挖掘的知识表示
1、规则
规则知识由前提条件和结论两部分组成,前提条件由字段(或属性)的取值的合取(与,AND,∧)析取(或,OR,∨)组合而成,结论为决策字段(或属性)的取值或者类别组成。
如:if A=a∧ B=bthen C=c
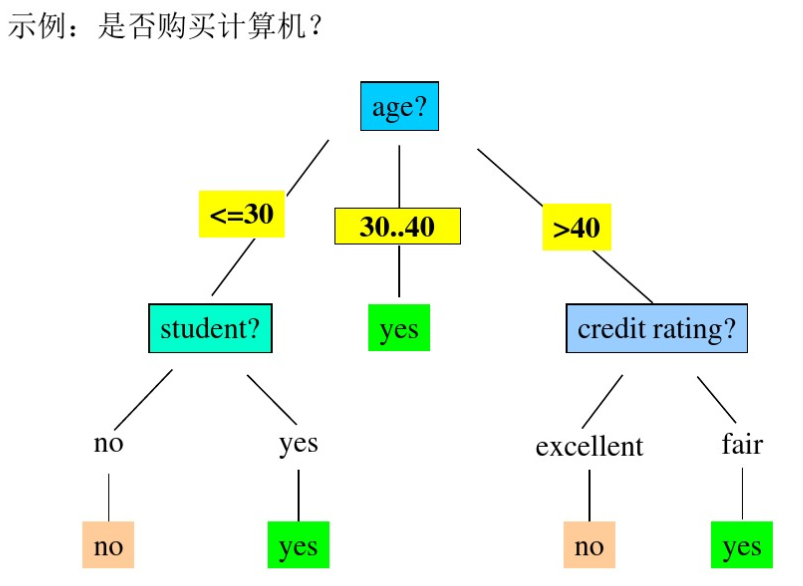
2、决策树
决策树采用树的形式表示知识,叶子结点表示结论属性的类别,非叶子结点表示条件属性,每个非叶子结点引出若干条分支线,表示该条件属性的各种取值。一棵决策树可以转换成若干条规则。
3、知识基
通过数据挖掘原表中的冗余属性和冗余记录,得到对应的浓缩数据,称为知识基。它是原表的精华,很容易转换成规则知识。
4、网络权值
神经网络方法得到的知识是一个网络结构和各边的权值,这组网络权值表示对应的知识。
三、数据挖掘的主要任务
数据挖掘的两个高层目标是预测和描述。预测是指用一些变量或数据库的若干已知字段预测其他感兴趣的变量或字段的未知或未来的值。描述是指找到描述数据的可理解模式,这些模式展示一些有价值的信息,可用于报表中以指导商业策略。
根据发现知识的不同,可以将数据挖掘的任务归纳为以下几类:关联分析、时序分析、分类、聚类和预测。
四、数据挖掘的发展
数据挖掘一词是在1989年8月于美国底特律市召开的第十一界国际联合人工智能学术会议上正式形成的。
1995年开始,每年主办一次KDD(Knowledge Discovery in Database)和DM的国际学术会议,将KDD和DM方面的研究推向了高潮,从此,“数据挖掘”一词开始流行。在中文文献中,DM有时还被翻译为数据采掘、数据开采、知识提取、数据考古等。
五、数据挖掘的对象
从原则上讲,数据挖掘可以在任何类型的数据上进行,可以是商业数据、可以是社会科学、自然科学处理产生的数据或者卫星观测得到的数据。
1、关系数据库:如保险公司的客户记录、交通运管部门的车辆数据库、日常运行的业务系统拥有大量的数据库。在进行数据挖掘前要对数据进行清洗和转换
2、数据仓库:数据仓库中的数据已经被清洗和转换,数据中不存在错误或不一致的情况。大部分情况下,数据挖掘都先把数据从数据仓库中拿到数据挖掘库或数据集市中。
3、事务数据库:每条记录代表一个事物,如一个顾客一次购买的商品构成一个事物数据记录。
4、高级数据库:包括面向对象数据库、空间数据库、时序和时间序列数据库、多媒体数据库等。
六、数据挖掘的分类
1、按数据库类型分类
![]() 从关系数据库中发现知识
从关系数据库中发现知识![]() 、从面向对象数据库中发现知识
、从面向对象数据库中发现知识![]() 、从多媒体数据库中发现知识
、从多媒体数据库中发现知识![]() 、从空间数据库中发现知识
、从空间数据库中发现知识![]() 、从历史数据库中发现知识、
、从历史数据库中发现知识、![]() 从Web数据库中发现知识。
从Web数据库中发现知识。
2、按挖掘的知识类型分类
按挖掘的知识类型分类主要有关联规则、特征规则、分类规则、偏差规则、聚集规则、判别式规则及时序规则等类型。
按知识的抽象层次可分为归纳知识、原始级知识、多层次知识。
3、按利用的技术类型分类
按数据挖掘方式分类主要有自发知识挖掘、数据驱动挖掘、查询驱动挖掘和交互式数据挖掘。
按数据挖掘途径可分为基于归纳的挖掘、基于模式的挖掘、基于统计和数学理论的挖掘及集成挖掘等。
4、按挖掘的深度分类
在较浅的层次上,利用现有数据库管理系统的查询及报表功能,与多维分析、统计分析方法相结合,进行OLAP,从而得出可供决策参考的统计分析数据。
在深层次上,从数据库中发现前所未知的、隐含的知识。
七、数据挖掘与数据仓库及OLAP的关系
1、数据挖掘与数据仓库的关系
融合和互补的关系:![]() 数据仓库中的数据可以作为数据挖掘的数据源;
数据仓库中的数据可以作为数据挖掘的数据源;![]() 数据挖掘的数据源不一定必须是数据仓库。
数据挖掘的数据源不一定必须是数据仓库。
共同之处:![]() 都是从数据库的基础上发展起来的,它们都是决策支持新技术 。
都是从数据库的基础上发展起来的,它们都是决策支持新技术 。
2、数据挖掘与OLAP的关系
相同点:![]() 数据挖掘与OLAP都是数据分析工具。
数据挖掘与OLAP都是数据分析工具。
不同点:![]() 数据挖掘是挖掘型的,建立在各种数据源的基础上,重在发现隐藏在数据深层次的对人们有用的模式,并做出有效的预测性分析。
数据挖掘是挖掘型的,建立在各种数据源的基础上,重在发现隐藏在数据深层次的对人们有用的模式,并做出有效的预测性分析。![]() OLAP是验证型的,OLAP更多地依靠用户输入问题和假设,建立在多维数据的基础之上 。
OLAP是验证型的,OLAP更多地依靠用户输入问题和假设,建立在多维数据的基础之上 。
八、数据挖掘的应用
1. 科学研究中的数据挖掘
2. 市场营销的数据挖掘
3. 金融数据分析的数据挖掘
4. 电信业的数据挖掘
5. 产品制造中的数据挖掘
6. Internet应用中的数据挖掘
【案例】大数据经典案例,你知道几个——啤酒与尿布
1. 啤酒与尿布
全球零售业巨头沃尔玛在对消费者购物行为分析时发现,男性顾客在购买婴儿尿片时,常常会顺便搭配几瓶啤酒来犒劳自己,于是尝试推出了将啤酒和尿布摆在一起的促销手段。没想到这个举措居然使尿布和啤酒的销量都大幅增加了。如今,“啤酒+尿布”的数据分析成果早已成了大数据技术应用的经典案例,被人津津乐道。
2.数据新闻让英国撤军
2010年10月23日《卫报》利用维基解密的数据做了一篇“数据新闻”。将伊拉克战争中所有的人员伤亡情况均标注于地图之上。地图上一个红点便代表一次死伤事件,鼠标点击红点后弹出的窗口则有详细的说明:伤亡人数、时间,造成伤亡的具体原因。密布的红点多达39万,显得格外触目惊心。一经刊出立即引起朝野震动,推动英国最终做出撤出驻伊拉克军队的决定。
3.Google成功预测冬季流感
2009年,Google通过分析5000万条美国人最频繁检索的词汇,将之和美国疾病中心在2003年到2008年间季节性流感传播时期的数据进行比较,并建立一个特定的数学模型。最终google成功预测了2009冬季流感的传播甚至可以具体到特定的地区和州。
4.大数据与乔布斯癌症治疗
乔布斯是世界上第一个对自身所有DNA和肿瘤DNA进行排序的人。为此,他支付了高达几十万美元的费用。他得到的不是样本,而是包括整个基因的数据文档。医生按照所有基因按需下药,最终这种方式帮助乔布斯延长了好几年的生命。

5.奥巴马大选连任成功
2012年11月奥巴马大选连任成功的胜利果实也被归功于大数据,因为他的竞选团队进行了大规模与深入的数据挖掘。时代杂志更是断言,依靠直觉与经验进行决策的优势急剧下降,在政治领域,大数据的时代已经到来;各色媒体、论坛、专家铺天盖地的宣传让人们对大数据时代的来临兴奋不已,无数公司和创业者都纷纷跳进了这个狂欢队伍。

6.微软大数据成功预测奥斯卡21项大奖
2013年,微软纽约研究院的经济学家大卫·罗斯柴尔德(DavidRothschild)利用大数据成功预测24个奥斯卡奖项中的19个,成为人们津津乐道的话题。今年罗斯柴尔德再接再厉,成功预测第86届奥斯卡金像奖颁奖典礼24个奖项中的21个,继续向人们展示现代科技的神奇魔力。
【案例】关于啤酒和尿布的大数据经典故事
这是个经典的商场数据分析案例。在上世纪90年代,美国沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。

“啤酒和尿布”的故事为什么产生于沃尔玛超市的卖场中?
卖场中“啤酒与尿布”的现象比比皆是,为什么“啤酒与尿布”的故事只产生在沃尔玛的卖场中,而不是其他零售门店?这里有两个原因。
第一个是沃尔玛先进的计算机技术是“啤酒与尿布”故事产生的强大支持后盾。零售业目前使用的很多新技术都是沃尔玛率先“尝鲜”的,比如沃尔玛最 早在门店尝试计算机记账,最早在门店收款台尝试使用外形丑陋俗称“牛眼”的条码扫描器进行收款,世界上第一个发射私人通信卫星等等。
目前运用于门店管理的很多技术手段都是沃尔玛做了“第一个吃螃蟹”的,我们只不过坐享其成而已。由于沃尔玛具备先进的技术手段,“啤酒与尿布”的故事在沃尔玛产生就一点也不奇怪了。
第二个原因是沃尔玛拥有一双锐利的慧眼。沃尔玛是一家极其讲究卖场现场管理的企业,沃尔玛创始人老沃尔顿最大的乐趣就是不停地在卖场巡视,更多地运用自己的双眼而不是数据来发现事实。因此不能忽略的是,没有沃尔玛管理人员的慧眼,“啤酒与尿布”的故事也会淹没在大量的零售数据中。该公司于1992年就着手进行数据挖掘项目,算是数据挖掘的先驱者。
启示一:购物篮大于商品
有在零售业工作经验的朋友都知道,老板考核大家的主要指标是商品销售额,你的工资袋取决于商品的销售额。老板会将商品销售指标下发到个人,每个人都只会关注自己的“一亩三分地”,卖啤酒的只管闷头卖啤酒,卖尿布的只管闷头卖尿布,每个柜台只管自己的商品是否能进入客户手中的购物篮。卖啤酒的不关心购物篮中的尿布,卖尿布的也漠视购物篮中的啤酒,只要别漏了自己柜台的东西就行了,因为漏了自己的商品,这个月的奖金就没了,人人只扫门前雪,长此以往商店的整体效益当然不会好了,效益不好就要裁员,大家都没好果子吃。反观沃尔玛的卖场管理体系中,购物篮是主要的管理对象,而不仅仅是商品。
为什么沃尔玛会以购物篮为管理重点?沃尔玛认为商品销售量的冲刺只是短期行为,而零售企业的生命力取决于购物篮。一个小小的购物篮体现了客户的真实消费需求和购物行为,每一只购物篮里都蕴藏着太多的客户信息。零售业的宗旨是服务客户,沃尔玛认为商店的管理核心应该是以购物篮为中心的顾客经营模式,商品排名只能体现商品自身的表现,而购物篮可以体现客户的购买行为及消费需求,关注购物篮可以使门店随时掌握客户的消费动向,从而使门店始终与客户保持一致。
启示二:购物篮方面的差距
购物篮的表现形式就是我们常说的“客单价”,客单价的高低直接反映了零售企业的经营效益。根据AC·尼尔森2006年对国内零售企业的调查发现, 从周一到周五正常工作日,同样一个万米经营面积的大卖场,国内卖场的平均客单价是29元,家乐福、沃尔玛、欧尚等国际零售巨头卖场的客单价为75元,好又多、大润发、乐购等台资卖场客单价为50元。到了周末(周六、周日)的差距更大,国内卖场客单价为35元,台资卖场客单价为80元,外资卖场可以达到 149元,这就是我们国内企业在购物篮方面的差距。
我们知道,销售额=客单价×客流数。在同等客流量的情况下,我们的企业由于客单价低,已经先失一着,销售业绩要比外资企业低200%,比台资企业低60%。此外,销售额低会带来很多问题,比如毛利额低、通道费低、与供应商的话语权降低,甚至会直接影响到企业的生存。因此,要想提高商业企业的销售 业绩,必须改善企业购物篮,全面提升客单价,可以说零售企业的购物篮代表了企业的生存权!
“啤酒与尿布”故事的依据是商品之间的相关性(也称关联性,英文名称为association rule),商品相关性是指商品在卖场中不是孤立的,不同商品在销售中会形成相互影响关系(也称关联关系),比如“啤酒与尿布” 故事中,尿布会影响啤酒的销量。在卖场中商品之间的关联关系比比皆是,比如咖啡的销量会影响到咖啡伴侣、方糖的销售量,牛奶的销量会影响面包的销售量等等。
所谓事物之间的相关性是指当一个事物变化时,另一个事物也会发生变化。当事物之间的变化是相互抵消的,比如猪肉价格上涨、猪肉销量下降,我们称这种相关性是负相关;当事物之间的变化呈现同一个方向发展时,比如气温上升、冷饮销量也上升,我们称这种相关性是正相关。
有些事物的相关性显而易见,有些则不是那么明显。美国华尔街股票分析师将女性超短裙的长度与道琼斯股票指数建立了关联,超短裙的长度与股票指数 成反比趋势,据说十分灵验,这就是相关性在生活中的种种体现。
商店中的关联性更是比比皆是,比如烟酒销售的关联关系:当门店附近有建筑工地时,低档烟、酒的销售就会上升;当附近有高档社区时,中华烟、葡萄酒的销售量就会上升。
提到商品相关性,很多人认为就是数据分析的事儿,其实对于商品相关性来说,更重要的是客户心理层面的因素,毕竟是人在提着购物篮,而不是猴子。客户在购物时的心理行为是产生商品之间关联关系最基本的原因,因此在找到购物篮规律时,必须要从客户消费心理层面解释这些关联关系,否则“啤酒与尿布”会永远停留在啤酒与尿布两个商品身上,而没有任何的推广意义。要想详细了解商品相关性形成的客户心理因素,要进行大量的客户消费行为观察,构建客户购物篮场景,才可使“啤酒与尿布” 的故事发扬光大。

