
OLAP实现
一、数据立方体的有效计算
1、预计算与维灾害
多维数据分析的核心是有效地计算多个维集合上的聚集。按照SQL术语,这些聚集称为GROUP BY(分组),每个分组可以用一个数据立方体表示。
对不同抽象层通过聚集创建的子数据立方体称为方体(cuboid)。因此原数据立方体可以看作方体的格,每个较高抽象层将进一步减少结果的规模。当回答一个查询时,应当使用与给定任务相关的最小可用方体。
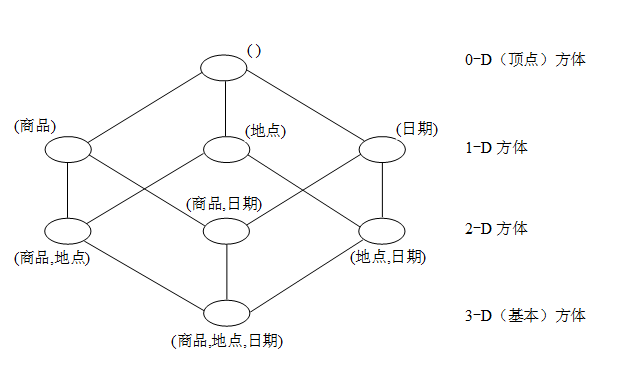
给定一个维的集合,例如,对于销售数据立方体(商品,地点,日期,销售量),其维集合为{商品,地点,日期},由它可以构造一个方体的格,如图3.14所示,其中0维方体存放最高层的汇总,称作顶点方体,是总销售量在所有的三个维汇总,也就是该立方体中所有数据的总销售量,顶点方体通常用All标记,它仅包含一个值。存放最底层汇总的方体称为基本方体,图中3维方体是给定维时间、地点和商品的基本方体。除基本方体外的其他方体称为非基本方体,基本方体中数据单元称为基本单元,非基本方体中数据单元称为聚集单元。

每个方体在不同的汇总级显示数据,汇总级越高,其维数就越小,对应的数据量(元组个数)也越少,也就是说,一个k+1维方体的数据量大于其中在任一维上聚集得到的k维方体的数据量。
一个OLAP查询问题可以转化成方体的计算。求某个k维方体有以下两种方法:
(1)通过基本方体进行聚集产生k维方体。由于基本方体维数最多,其数据量最大,所以该方法是十分耗时的。
(2)从k+1维方体计算出k维方体。
如给定(商品,地点)这个2维方体,在各维上聚集可以产生(商品)和(地点)两个1维方体,显然比从(商品,地点,日期)基本方体产生(商品)和(地点)方体要省时,但需要预先计算出(商品,地点)方体。
从方法(2)看出,对于不同的查询分析,OLAP可能需要访问不同的方体。
因此,提前计算数据立方体中所有的或者一部分方体,这称为预计算。预计算带来快速的响应时间,并避免一些冗余计算。
对于不同的查询,OLAP可能需要访问不同的方体。因此提前计算数据立方体中的所有或者一部分方体,看来是好主意。预计算带来快速的响应时间,并避免一些冗余计算。
然而,预计算的挑战是?
然而,预计算的主要挑战是,如果数据立方体中所有的方体都预先计算,所需的存储空间可能爆炸,特别是当立方体包含许多维,这许多维都具有多层的概念分层时,存储需求甚至更多,这个问题称作维灾害。
那么,“n维数据立方体有多少个方体?”如果n个维没有概念分层,n维数据立方体的方体总数为2^n。然而,在实践中,许多维确实具有概念分层。例如,维时间的概念分层“日<月<季度<年”。于是,n维数据立方体可能产生的方体总数是
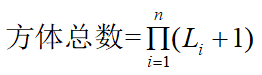
式中,Li是与维i相关联的层数。将1加到公式的Li上,包括虚拟的顶层all。
该公式基于这样一个事实:每个维最多只有一个抽象层出现在一个方体中。例如,时间维有4个概念层,或者说有5个概念层(包括虚拟层all)。如果数据立方体有10维,每层5层(包括虚拟层all),则可能产生的方体总数将是5^10=9.8*(10^6)
这种当数据立方体的维数较多和各维的层次较多时,可能的聚集计算量剧增,导致存储空间出现爆炸的现象称作维灾难。
2、聚集的物化
所谓物化就是预计算并存储数据立方体的方体。物化方法有不物化、全物化和部分物化。
(1)不物化方法
不预计算任何“非基本”方体。这可能导致回答查询时,因进行昂贵的多维聚集计算,速度非常慢。
(2)全物化方法
全物化是指对维集合的所有可能组合都进行聚集。
通常这种选择需要海量存储空间来存放所有预计算的方体。
(3)部分物化方法
部分物化是指在部分维及其相关层次上进行聚集,即从数据立方体的所有方体中选择一个子集进行物化。
在一般情况下,通常20%的聚集就能够满足80%的查询需要。如何确定该20%的聚集是提高聚集效率的关键。部分物化是存储空间和响应时间二者之间的很好折衷。
3、数据立方体的压缩存储
通常数据立方体中包含海量数据,为了节省存储空间,人们提出了各种数据压缩方法。这里介绍一种相对简单的压缩方法。
对于给定的数据立方体,由于度量的不同值个数可能很大,难以压缩存储。主要是对维进行压缩存储。

二、索引OLAP数据
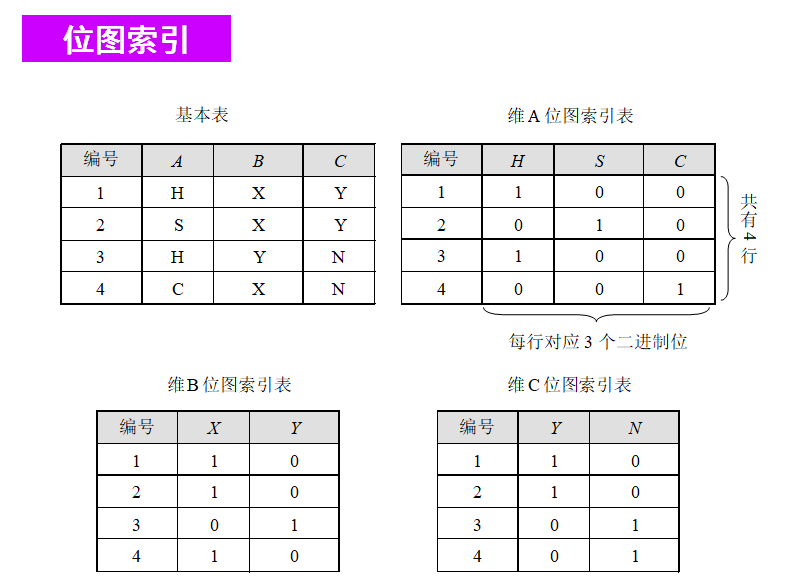
1、位图索引
基本设计思想:用一个0、1位串来表示一个元组某一属性值的取值,位串中的位的位置表示了关系表中元组的位置。
在给定属性的位图索引中,属性域中的每个值v有一个不同的位向量Bv,位向量的长度等于基于表的记录个数。如果给定的属性域包含n个值,则位图索引中以n位向量表示每个不同的值。如果数据表给定行上该属性值为v,则在位图索引的对应行,表示该值的为1,该行的其他位均设为0。
【例】假设在一个与销售事实相对应的数据立方中,有一个顾客的性别属性gender,一个是产品的种类属性item。其中gender属性有两个不同的值:M和F。产品的种类属性item有4个不同的取值:a、b、c、d。设数据立方中共有8个元组。如果在gender属性上建立位图索引则需要两个位向量,每个向量共8位。在item上建立位图索引需要4个位向量,每个向量共8位。

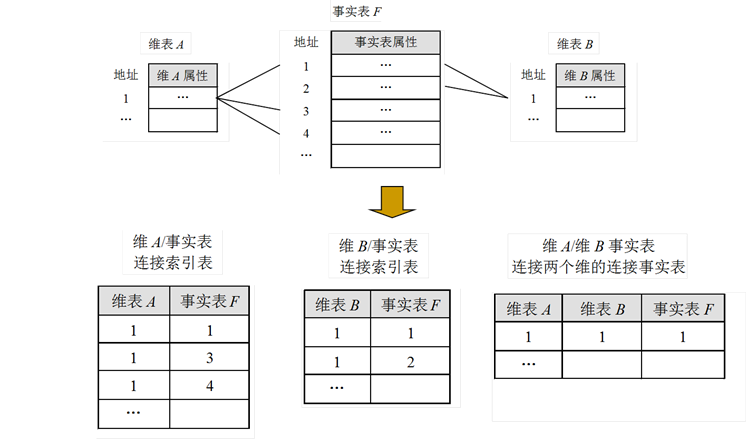
2、连接索引
所谓连接索引,就是将事实表和维表中的索引项进行连接运算,然后将结果作为索引保留。
3、OLAP查询的有效处理
物化方体和索引OLAP数据的目的是加快数据立方体查询处理的速度。通常,OLAP查询处理的步骤如下:
①确定哪些操作应当在可利用的方体上执行:这涉及将查询中的选择、投影、上卷(分组)和下钻操作转换成对应的SQL或OLAP操作。例如,数据立方体的切片和切块可能对应于物化方体上的选择或投影操作。
②确定相关操作应当使用哪些物化的方体:这涉及找出可能用于回答查询的所有物化方体,使用方体之间的依赖关系,剪去上集合,评估使用剩余物化方体的代价,并选择代价最低的方体。

