
OLAP的多维数据模型
一、多维数据模型的定义
OLAP基于多维数据模型,对应的数据集称为多维数据集,有时也称为数据立方体(data cube),它由维和事实定义。
一般,维是人们观察数据的特定角度,例如,一个“销售”数据仓库可能涉及维:时间、地点、商品和商品供应商等。每个维都有一个表与之相关联,称为维表。例如,“商品”维表可以包含属性商品名、品牌、类型和颜色。维表可以由用户或专家设定,或者根据数据分布自动产生和调整。
通常,多维数据模型围绕中心主题(例如销售)组织。主题用事实表表示。事实一般是数值度量的。例如“销售”数据仓库的事实包括销售额和销售量。事实表包括事实的名称或度量,以及每个相关维表码。
多维数据集可以用一个多维数组来表示,它是维和变量的组合表示。一个多维数组可以表示为(维1,维2,…,维n,变量列表)
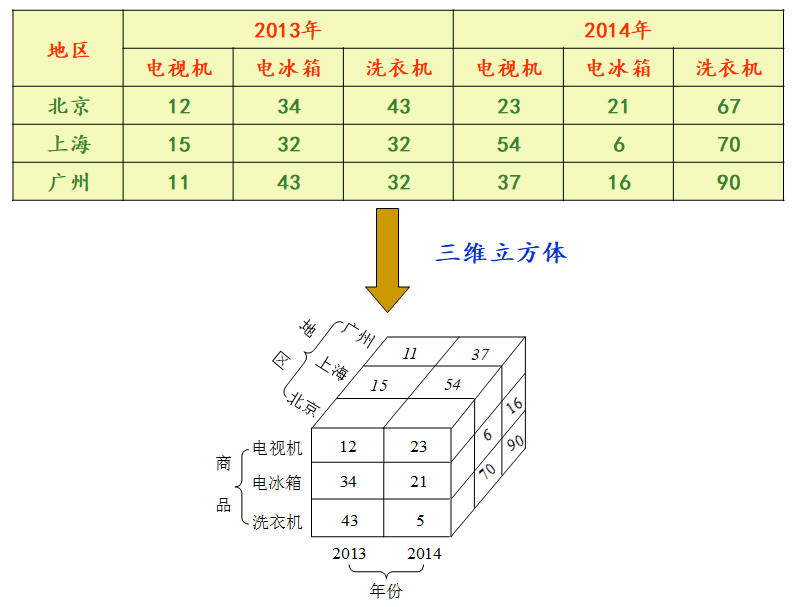
尽管经常将数据立方体看作三维几何结构,但在数据仓库中,数据立方体是n维的。
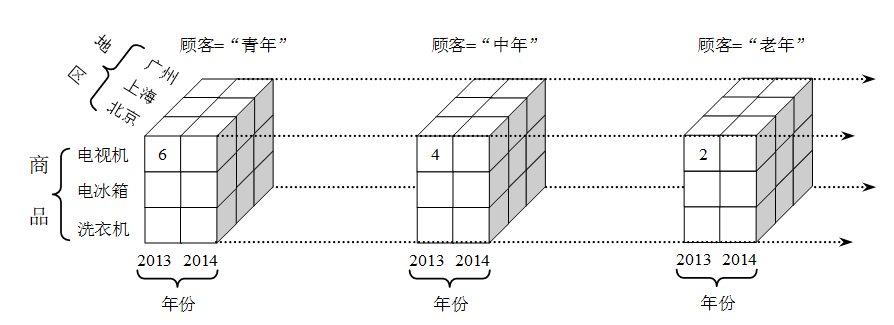
假定在前例中再增加一个维,如顾客维,以4维形式观察这组销售数据。观察4维事物变得有点麻烦,然而,可以把4维立方体看成3维立方体的序列,如下图所示。
二、OLAP的基本分析操作
OLAP的基本分析操作主要包括对多维数据进行切片、切块、旋转、上卷和下钻等,这些分析操作使得用户可以从多种维度、多侧面、多种数据综合度观察数据,从而深入了解包含在数据中的信息。OLAP的操作方式迎合人们的思维模式,因此减少了混淆,降低了出现错误解释的可能性。
1、切片
切片定义1:在多维数据集的某一维上选定一个维成员的操作称为切片。(注:多维数组就从n维降成了n-1维)
例如,在多维数组:(维1,维2,…,维i,…,维n,度量列表)
中选定一维,即维i,并取其一维成员(维成员vi),所得的多维数组的子集(维1,…,维i-1,维成员vi,维i+1,…,维n,度量列表),称为维i上的一个切片。
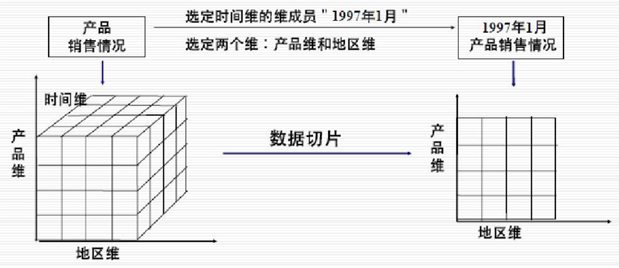
图是一个按产品维、城市维和时间维(年)组织起来的产品销售数据,用多维数组表示为(时间、城市、产品、销售额)。如果在城市维上选定一个维成员(设为“上海”或“广州”),就得到了在城市维上的一个切片;如果在产品维上选型一个维成员(设为“电视机”或“电冰箱”),就得到了在产品维上的一个切片。
切片定义2:选定多维数据集的一个两维子集的方法称为切片。例如在多维数组(维1,维2,…,维i,…,维n,度量列表)中选定两个维i和维j,在这两个维上取某一区间或任意维成员,而将其余的维都选取一个维成员,则得到的就是多维数据集在维i和维j上的一个二维子集,称这个二维子集为多维数据集在维i和维j上的一个切片,表示为(维i,维j,度量列表)
【例】选定多维数组(时间、城市、产品、销售额)中的时间维度与产品维度,而在城市维上区定一个维成员(设为“上海”或“广州”,就得到了多维数组(时间、城市、产品、销售额)在时间和产品两维上的一个切片(时间、产品、销售额)。它表示“上海”或“广州”地区各产品、每年的销售情况。相应地,选定时间维度与城市维度,而在产品维上取定一个维成员(设为“电视机”或“电冰箱”,就得到了多维数组(时间、城市、产品、销售额)在时间和城市两维上的一个切片(时间、城市、销售额)。
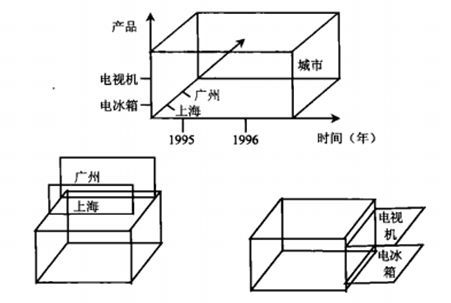
在切片的概念中,有两个重要事实必须要了解:一个是进行切片操作的目的是使用户能够更好地了解多维数据集,通过切片的操作可以降低多维数据集的维度,使用户能将注意力集中在较少的重要维度上进行观察,也就是说能够将注意力集中在经营管理中所感兴趣的影响因素上对经营管理中的问题进行分析;另一个是多维数据集切片数量多少是由所选定的那个维的成员数量的多寡决定的。
2、切块
切块定义1:在多维数据集(维1,维2,…,维n,度量列表)中通过对两个或多个维执行选择得到子集的操作称为切块。
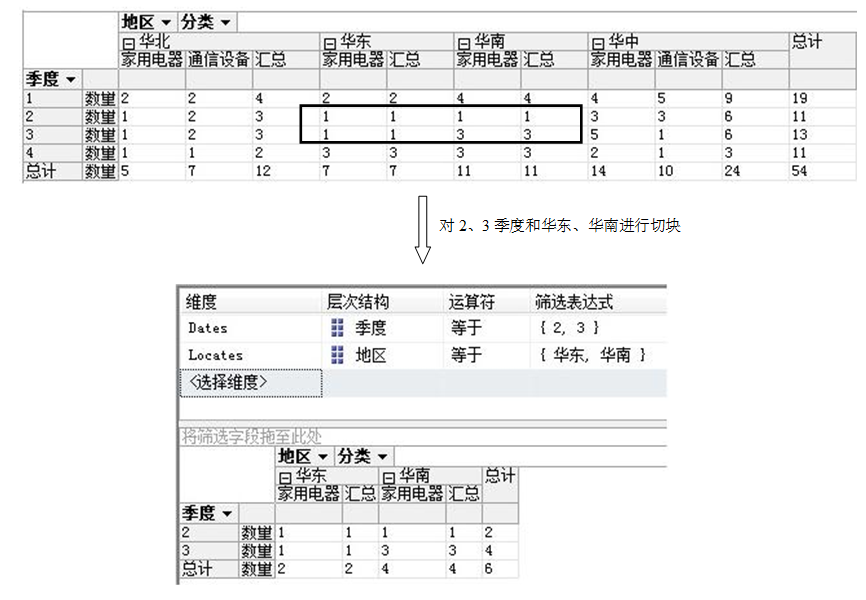
切块定义2:选定多维数据集的一个三维子集的方法称为切块。
例如,选定:(维1,维2,…,维n,度量列表)中的三个维:维i、维j和维k,在这三个维上取某一区间或任意的维成员,而将其余的维都取定一个维成员,则得到的是多维数据集在维i、维j和维k上的一个三维子集,称之为切块,表示为:(维i,维j,维k,度量列表)
切块和切片操作的作用是相似的。实际上,切块操作也可以看成进行多次切片,即切块操作结果可以看成进行多次切片叠合而成。
3、旋转
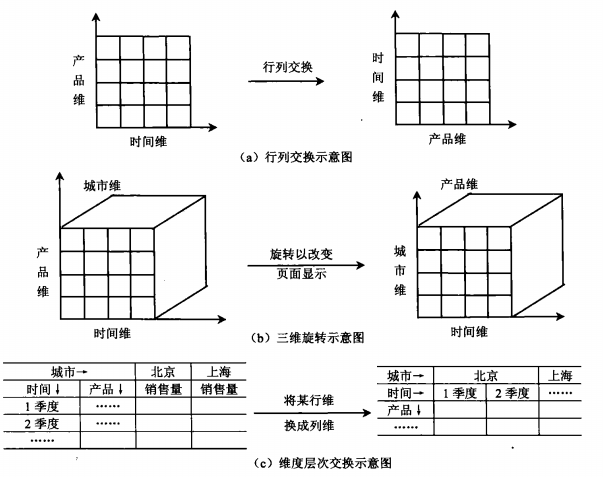
旋转(又称转轴,Pivot)是一种视图操作,即改变一个报告或页面显示的维方向,可以得到不同视角的数据,即转动数据的视角以提供数据的替代表示。
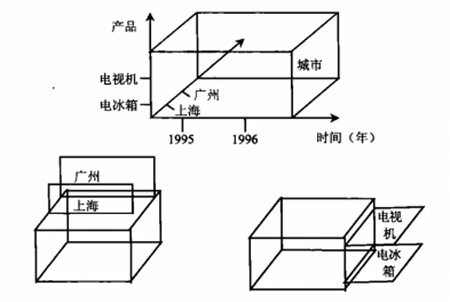
【例】图(a)是一个行列交换示意图,横向的时间维度和纵向的产品维度进行了交换,从而形成横向为产品,纵向为时间的表。图(b)是一个三维旋转示例。图(c)则是在维度层次之间进行了交换,这使得用户能够更好地对同产品不同城市,不同季度的数据进行比较。
4、上卷
维度是有层次性的,如时间维可能由年、季、月、日构成,维度的层次实际上反映了数据的综合程度。维度层次越高,代表的数据综合度越高,细节越少,数据量越少,维度层次越低,则代表的数据综合度越低,细节越充分,数据量越大。(数据转取包含上卷和下卷转取)
上卷操作通过维的概念分层向上攀升或者通过维归约(即将4个季度的值加到一起为一年的结果)在数据立方体上进行聚集。
如在产品维度上,由产品向小类上卷,可得到小类的聚集数据,再由小类向大类上卷,可得到大类层次的聚集数据。
5、下钻
下钻是上卷的逆操作,它由不太详细的数据到更详细的数据。
使用户在多层数据中能通过导航信息而获得更多的细节数据。下钻可以沿维的概念分层向下或引入新的维或维的层次来实现。
【例】图(1)2004年某产品销售收入,时间层次是“年”,如在时间维上进行下钻操作,可获得其下层各季度销售数据。图(2)显示的是2004年某产品每季度的销售情况,各个季度的销售总和应当等于图1中一年的销售量。同理,如果我们在季度层次上继续向下钻取,则可得到2004年该产品每季度、每月的销售情况。同理,若进行上探,则可从图2得到图1的结果。


