
数据仓库的建模
本章节主要是概念模型及逻辑模型的设计,它是用于一定的目标设计系统、收集信息而服务的一个概念性的工具,可以为整个系统提供统一的概念视图。
一、多维数据模型及相关概念
多维数据模型将数据看作数据立方体形式,满足用户从多角度多层次进行数据查询和分析的需要而建立起来的基于事实和维的数据库模型。
1、粒度
粒度是指数据仓库中数据单元的详细程度和级别,确定数据仓库的粒度是设计数据仓库的一个最重要方面。
数据越详细,粒度越小,级别就越低;数据综合度越高,粒度越大,级别就越高。例如,地址数据中“北京市”比“北京市海淀区”的粒度小。
2、维度
维度(简称为维)是指人们观察事物的特定的角度,概念上类似于关系表的属性。
例如企业常常关心产品销售数据随着时间推移而变化的情况,这是从时间的角度来观察产品的销售,即时间维;
企业也常常关心本企业的产品在不同地区的销售分布情况,这时是从地理分布的角度来观察产品的销售,即地区维。
3、维属性和维成员
一个维是通过一组属性来描述的,如时间维包含年份、季度、月份和日期等属性,这里的年份、季度等称为时间维的维属性。
维的一个取值称为该维的一个维成员,如果一个维是多层次的,那么该维的维成员是在不同维层次的取值组合。例如,一个时间维具有年份、季度、月份、日期四个层次,分别在四个层次各取一个值,就得到时间维的一个维成员,即某年某季某月某日。
4、维层次
同一维度可以存在细节程度不同的各个值,可以将粒度大的值映射到粒度小的值,这样构成维层次(或维层次结构)或概念分层,即将低层概念映射到更一般的高层概念。
例如对于地点维,有“杭州→浙江→中国”的维层次。又例如时间维,可以从年、季度、月份、日期来描述,那么“年份→季度→月份→日期”就是维层次。
5、度量或事实
度量是数据仓库中的信息单元,即多维空间中的一个单元,用以存放数据,也称为事实(Fact)。
通常是数值型数据并具有可加性。例如:(日期,商品,地区,销售量)
其中,销售量就是一个度量。
注:度量的特点
(1)度量是决策者所关心的具有实际意义的数值,例如,销售量、库存量、银行贷款金额等;
(2)度量所在的表称为事实数据表,事实数据表中存放的事实数据通常包含大量的数据行;
(3)事实数据表的特点是包含数值数据(事实),而这些数值数据可以统计汇总以提供有关单位运作历史的信息。
(4)度量是所分析的多维数据集的核心,它是最终用户浏览多维数据集时重点查看的数值数据。
二、多维数据模型的实现
多维数据模型可以采用关系数据库、多维数据库以及两者相结合的方式来表示。
1、关系数据库
在关系数据库中,数据总是以关系表的方式来组织的。在基于关系数据库的数据仓库中有两类表,一类是维表,对每个维至少使用一个表存放维的层次、成员等维的描述信息;另一类是事实表,用来存放维关键字和度量等信息。维表和事实表通过主关键字(主键)和外关键字(外键)联系在一起。
2、多维数据库
多维数据库是指将数据存放在一个门维数组中,而不是像关系数据库那样以记录的形式存放。它存在大量稀疏矩阵,人们可以通过多维视图来观察数据。多维数据库增加了一个时间维,与关系数据库相比,它的优势在于可以提高数据处理速度,加快反应时间,提高查询效率。
【例】多维数据库的组织方式
各公司多维数据库产品的数据组织不完全相同,Arbor公司的ESSbase多维数据库是一种具有代表性的产品,下面以这种组织方式为例,说明从多维数据库或关系数据库中抽取出来、存放在多维数据库的数据组织。
将用于分析的数据从关系数据库或关系数据仓库中抽取出来,存放到多维数据库的超立方结构中。首先,设计一个例子来说明这种组织结构(如下图1所示)。
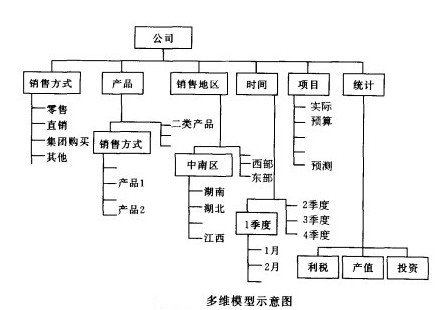
图1 多维模型示意图
有一组包含6个维的数据:销售方式 6成员;产品1500成员;销售地100成员;时间17成员;项目8成员;统计50成员。
其中,一些维被称为“稠密维”(dense dimensions),这些维构成了数据存储的“多维体”,其他的维被称为“稀疏维”(sparsedimensions)。
可以将这些“稀疏维”存储在类数据库表结构中,这个表中只记录那些组合存在的数据,并有一个索引指向相应的“多维体”。
在例子中“时间”、“项目”和“统计”是“稠密维”,如下图2所示,它们构成了“立方体”;其他的三维产品、销售方式、销售地区是“稀疏维”,如下图3所示。
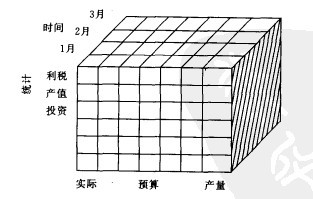
图2 稠密维示意图
这种多维体是以多维数组方式记录各测量值的,相应各维有一定的记录维及维内层次的元数据结构。
这种数据组织方式消除了大量数据库表中由于空穴造成的空间浪费,以及在每个元组中存储的外键信息,它由统一的维与数组的对应系数限定数据,大大减少了存储空间。
当使用多维数据库作为数据仓库的基本数据存储形式时,其最主要的特点是:大大减少了以维为基本框架的存储空间,针对多维数据组织的操作算法,极大地提高了多维分析操作的效率。

图3 稀疏维示意图
【注】多维数据库与关系数据库的比较
多维数据库是在最近十年内发展起来,其目的是分析数据而不是完成在线事务。多维数据库(MDA)对数据进行建模以作为事实、维度或者数值度量,这些都为做出决策而进行了大量数据的交互分析。这类数据库常见的示例包括InterSystems Cache、ContourCube以及Cognoa PowerPlay。多维数据库使用立方体的概念来代表用户可用数据的维度,并且使用了4个维度(参见图4)。例如,“销售”可以看作是如下几个维度:(1)产品模型;(2)地理位置:(3)时间;(4)其他附加的维度。在上述情况下,“销售”可以看作是数据立方体的主要属性(或者度量),而其他维度则可以看作是“特性”属性。
关系数据库常常需要SELECT……FROM以及其他类型的SQL查询来提供信息,与此不同,多维数据库允许用户以更为口语化的英语来询问问题,例如,“How many type Z dog leashes have been sold in New Jersey so far this year?”为达到此目的可以使用一种在线分析处理(OLAP)的软件,该软件可以迅速地提供出复杂数据库的查询答案。OLAP软件常常使用于销售与市场业务报表、管理报表、趋势分析等类似的领域中。访问多维数据库中数据的OLAP应用软件称为MOLAP(多维OLAP)应用软件。
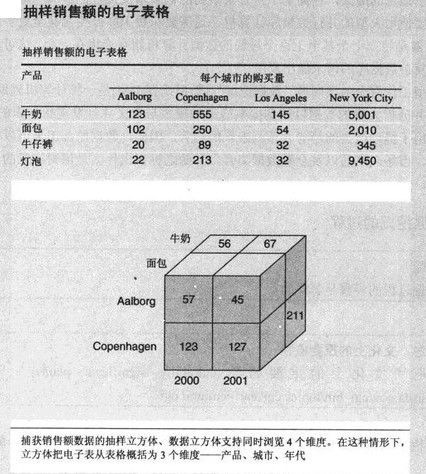
图4 多维数据模型
三、数据仓库建模的主要工作
1、在需求分析上,确定系统所包含的主题域并加以描述
主题选取的原则是优先实施管理者目前最迫切需求、最关心的主题。主题内容的描述包括主题的公共键、主题之间的联系和各主题的属性。
例如,若以顾客为主题,则设计的相关主题内容的描述如下:
基本信息:顾客号、顾客姓名、性别、年龄、文化程度、住址、电话
经济信息:顾客号、年收入、家庭总收入
公共键:顾客号
2、确定事实表的粒度
事实表的粒度能够表达数据的详细程度。从用途的不同来说,事实表可以分为以下三类:
(1)![]() 原子事实表:是保存最细粒度数据的事实表,也是数据仓库中保存原子信息的场所。
原子事实表:是保存最细粒度数据的事实表,也是数据仓库中保存原子信息的场所。![]()
(2)聚集事实表:是原子事实表上的汇总数据,也称为汇总事实表。![]()
(3)合并事实表:是指将位于不同事实表中处于相同粒度的事实进行组合建模而成的一种事实表。
3、确定数据分割策略
分割是指把逻辑上是统一整体的数据分割成较小的、可以独立管理的物理单元进行存储,以便能分别处理,从而提高数据处理的效率。
分割可以按时间、地区、业务类型等多种标准来进行,也可以按自定义标准,分割之后小单元的数据相对独立,处理起来更快更容易。但在多数情况下,数据分割采用的标准不是单一的,而是多个标准的组合。
4、构建数据仓库中各主题的多维数据模型及其联系
四、几种常见的基于关系数据库的多维数据模型
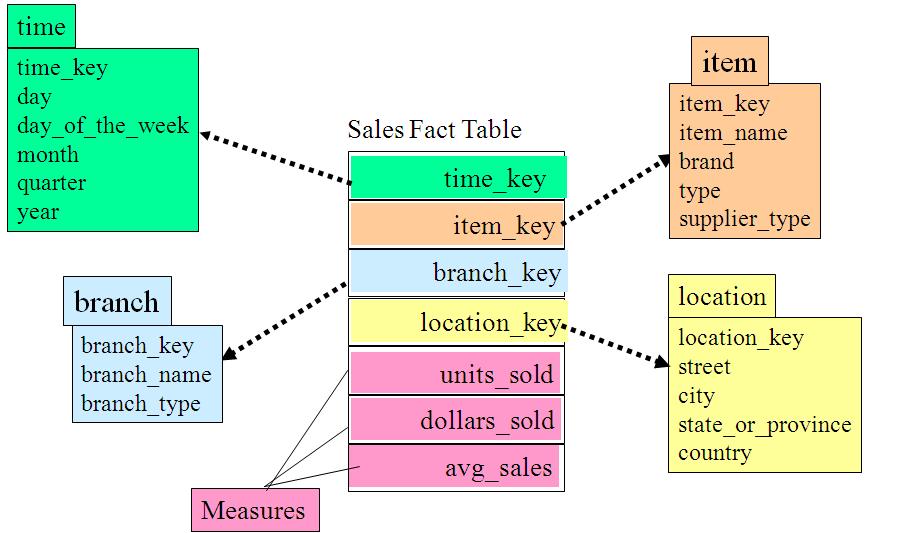
1、星形模式
星型模式是维度模型最简单的形式,也是数据仓库以及数据集市开发中使用最广泛的形式。
星形模式(Star schema)是由一个事实表和一组维表组成,其中,事实包含业务的度量,是定量的数据,如销售价格、销售数量、距离、速度、重量等是事实。维度是对事实数据属性的描述, 如日期、产品、客户、地理位置等是维度。
该模式的核心是事实表,通过事实表将各种不同的维表连接起来,各个维表都连接到中央事实表。
(1)事实表
事实表记录了特定事件的数字化的考量,一般由数字值和指向维度表的外键组成。通常会把事实表的粒度级别设计得比较低,使得事实表可以记录很原始的操作型事件,但这样做的负面影响是累加大量记录可能会更耗时。事实表有以下三种类型:
事务事实表。记录特定事件的事实,如销售。
快照事实表。记录给定时间点的事实,如月底账户余额。
累积事实表。记录给定时间点的聚合事实,如当月的总的销售金额。一般需要给事实表设计一个代理键作为每行记录的唯一标识。代理键是由系统生成的主键,它不是应用数据,没有业务含义,对用户来说是透明的。
(2)维度表
维度表的记录数通常比事实表少,但每条记录包含有大量用于描述事实数据的属性字段。维度表可以定义各种各样的特性,以下是几种最常用的维度表:
时间维度表。描述星型模式中记录的事件所发生的时间,具有所需的最低级别的时间粒度。数据仓库是随时间变化的数据集合,需要记录数据的历史,因此每个数 据仓库都需要一个时间维度表。
地理维度表。描述位置信息的数据,如国家、省份、城市、区县、邮编等。
产品维度表。描述产品及其属性。
人员维度表。描述人员相关的信息,如销售人员、市场人员、开发人员等。 范围维度表。描述分段数据的信息,如高级、中级、低级等。
【例】星形模式
2、雪花模式
雪花模式(Snowflake schema)是对星形模式的扩展,每一个维表都可以向外连接多个详细类别表。
在这种模式中,维表除了具有星形模式中维表的功能外,还连接对事实表进行详细描述的详细类别表,详细类别表通过对事实表在有关维上的详细描述达到了缩小事实表和提高查询效率的目的。
【例】雪花模式
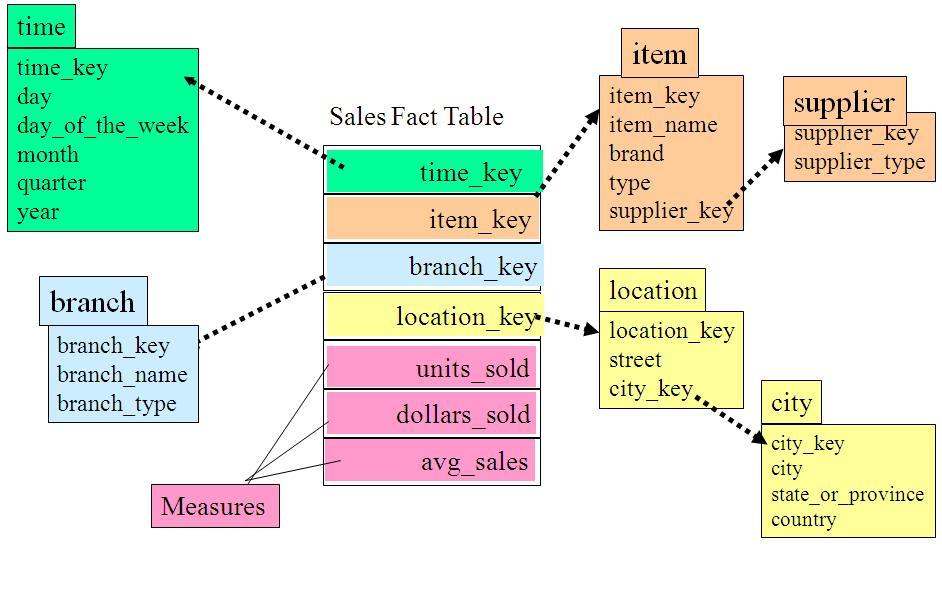
3、事实星座模式
通常一个星形模式或雪花模式对应一个问题的解决(一个主题),它们都有多个维表,但是只能存在一个事实表。
在一个多主题的复杂数据仓库中可能存放多个事实表,此时就会出现多个事实表共享某一个或多个维表的情况,这就是事实星座模式(Fact Constellations schema)。
【例】事实星座模式


