根据需要,按照以下步骤实现爬虫,获取想要的数据。
(1)爬虫撰写与页面解析
核心代码如下:
| # 指定URL
url = "http://***.com/daily/wangpiao?page=" + str(i)
# 设定头部信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
# 读取数据
data = requests.get(url, headers=headers)
data.encoding = 'utf-8'
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(data.text, "html.parser")
# 解析得到电影名
name = soup.select("#content > div.table-responsive > table > tbody > tr > td:nth-child(2) > a") |
获取的数据示例如下表所示。其中第一条表示电影《战狼2》在2017年8月5日的票房及其它信息。 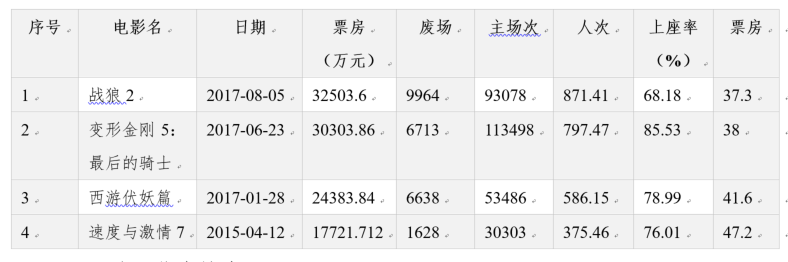 (2)跨页信息搜索
(2)跨页信息搜索
由于一条数据记录的信息来源于多个页面,需要从其它页面中搜索对应的评分等数据。示例代码如下:
| for name, date, zcc, fc, rc, szl, pj, pfurl in zip(name, date, zcc, fc, rc, szl, pj, pfurl):
name1 = name.get_text().encode("utf-8")
dburl1 = "https://www.***.com/search?cat=1002&q="
dburl2 = urllib.quote(name1)
dburl = dburl1 + dburl2
dbres = requests.get(dburl, headers=headers).text
# 获得评分
dbpf = re.findall("<span class=\"rating_nums\">(.*?)</span>", dbres)
url1 = "http://***.com"
a = re.findall("(.*?)/boxoffice", pfurl.a['href'])
purl1 = url1 + str(a[0])
res = requests.get(purl1, headers=headers)
text = res.content.decode("utf-8")
# 找到地区
dq = re.findall(u"制作国家.*?\">(.*?)</a>", text)
# 找到导演
dy = re.findall(u"导演:.*?\">(.*?)</a>", text) |
获取的票价和评分数据如下表所示。

(3)数据存储
将以上获得的数据存储在本地文件中,代码如下:
| # 数据存储
header = ['name', 'date', 'pf', 'zcc', 'rc', 'szl', "pj", "fc", "dbpf", "dq", "dy"]
fp = open('result6.csv', 'w+')
f_csv = csv.DictWriter(fp, header)
f_csv.writeheader()
f_csv.writerows(list) |


