| #coding:utf-8
import numpyas np
import pandas as pd
import matplotlib.pyplotas plt
import tensorflowas tf
from sklearn.model_selection import train_test_split
from sklearnimport preprocessing
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df= pd.read_csv('iris.csv', delimiter=',')
#对类别进行数值化处理
le = preprocessing.LabelEncoder()
df['Cluster'] = le.fit_transform(df['Species'])
x = df[['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm']]
y = df[['Cluster']]
sess = tf.Session()
seed = 2
tf.set_random_seed(seed)
np.random.seed(seed)
#创建训练集与测试集的划分
x_train, x_test,y_train, y_test=train_test_split(x, y, train_size=0.8, test_size=0.2)
# 添加占位符,四个输入
x_data = tf.placeholder(shape=[None, 4], dtype=tf.float32) # 添加占位符,一个输出
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# 定义如何添加一个隐藏层的函数
def add_layer(input_layer, input_num, output_num):
weights = tf.Variable(tf.random_normal(shape=[input_num, output_num]))
biase = tf.Variable(tf.random_normal(shape=[output_num]))
hidden_output = tf.nn.relu(tf.add(tf.matmul(input_layer, weights), biase))
return hidden_output
# 定义三个隐藏层对应的结点个数
hidden_layer_nodes = [10,8,10]
hidden_output = add_layer(x_data, 4, hidden_layer_nodes[0]) # 循环添加三个隐藏层
for i in range(len(hidden_layer_nodes[:-1])):
hidden_output = add_layer(hidden_output, hidden_layer_nodes[i],hidden_layer_nodes[i + 1])
final_output = add_layer(hidden_output,hidden_layer_nodes[-1],1)
# 定义损失函数,使得误差最小
loss = tf.reduce_mean(tf.square(y_target - final_output))
# 设置学习率来调整每一步更新的大小
my_opt = tf.train.GradientDescentOptimizer(learning_rate=0.00004)
# 优化目标:最小化损失函数
train_step = my_opt.minimize(loss)
init = tf.global_variables_initializer()
sess.run(init)
loss_vec = [] #训练操失
test_loss = [] #测试操失
#训练次数
for i in range(10000):
#训练
sess.run(train_step, feed_dict={x_data:x_train, y_target:y_train})
#训练数据评估模型
temp_loss = sess.run(loss, feed_dict= {x_data:x_train, y_target:y_train})
loss_vec.append(np.sqrt(temp_loss))
#测试数据评估模型
test_temp_loss = sess.run(loss, feed_dict= {x_data:x_test, y_target:y_test})
test_loss.append(np.sqrt(test_temp_loss))
if (i+1)%1000 == 0:
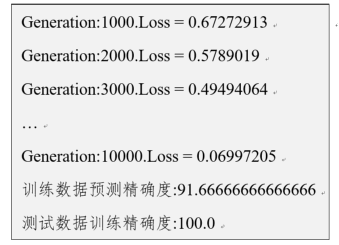
print('Generation:' + str(i+1) + '.Loss = ' + str(temp_loss))
test_preds = [np.round(item,0) for item in sess.run(final_output,feed_dict={x_data:x_test})]
train_preds = [np.round(item,0) for item in sess.run(final_output,feed_dict={x_data:x_train})]
y_test = [i for i in y_test['Cluster']]
y_train = [i for i in y_train['Cluster']]
test_acc = np.mean([i==j for i, j in zip(test_preds, y_test)]) * 100
train_acc = np.mean([i==j for i, j in zip(train_preds, y_train)]) * 100
print('训练数据预测精确度:{}'.format(train_acc))
print('测试数据训练精确度:{}'.format(test_acc))
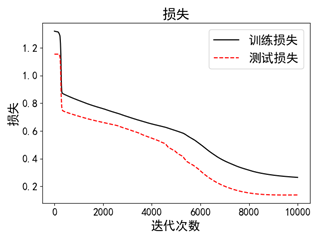
plt.plot(loss_vec, 'k-', label ='训练损失')
plt.plot(test_loss, 'r--', label ='测试损失')
plt.title('损失')
plt.xlabel('迭代次数')
plt.ylabel('损失')
plt.legend(loc='upper right')
plt.show() |