
环境准备
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。同时,使用Keras可以简单地搭建深度学习模型,进行模型训练和预测,对于新手,能够有助于快速理解并运用该深度学习框架。

本章搭建的模型都是通过Keras实现。要使用Keras,需要安装必要的NumPy、Pandas等包,同时还需要安装深度学习包TensorFlow和Keras。
通过快捷键WIN键+R键打开cmd命令窗口,通过输入命令pipinstall tensorflowt和pip install keras分别安装TensorFlow和Keras包。主要运行如下代码:
| pip install tensorflow pip install keras |
安装成功后,我们就可以进入下一步的学习和操作了。
数据获取与解析
人体携带装有相应传感器(加速度计、陀螺仪等)的手机即可获得相应的数据。当然,网络上也很多数据可以直接拿来用做训练,我们可以通过链接(https://archive.ics.uci.edu/ml/machine-learning-databases/00240)下载相应的数据包。该数据包中的数据集由30名年龄在19~30岁志愿者完成。每位志愿者腰间佩戴智能手机(三星Galaxy S II)进行6项活动(散步、上楼散步、下楼散步、坐下、站立、躺下)。利用其内置的加速度计和陀螺仪进行收集。采集过程中,以恒定的频率捕捉了线性加速度和角速度。
这些实验数据被存储下来,并用人工进行了标注。所获得的数据集被随机分成两组,其中:70%的志愿者被选中生成训练数据,30%的志愿者被选中生成测试数据。
传感器信号(加速度计和陀螺仪)通过应用噪声滤波器进行预处理,然后在2.56秒和50%重叠(128个读数/窗口)的固定宽度滑动窗口中采样。利用巴特沃斯低通滤波器将传感器加速度信号分解为物体加速度和重力信号,传感器加速度信号由重力分量和物体运动分量组成。假设重力只有低频分量,因此使用了截止频率为0.3Hz的滤波器。在每个窗口中,通过计算时间域和频率域的变量得到特征向量。简言之,这些下载下来的数据已经经过噪声去除处理,并通过2.56秒时长对传感器数据采样分离。
具体数据集中包括:
(1)“features_info.txt”:显示有关在特征向量上使用的变量信息。
(2)“features.txt”:所有功能的列表。
(3)“activity_labels.txt”:类标签与其活动名称对应关系。
(4)“train/x_train.txt”:训练集数据。
(5)“train/y_train.txt”:训练集标签。
(6)“test/x_test.txt”:测试集数据。
(7)“test/y_test.txt”:测试集标签。
以下文件可用于训练和测试,主要有:
(1)“train/subject_train.txt”:标识为每个窗口活动的主体。范围从1到30。
(2)“train/Inertial Signals/total_acc_x_train.txt”:来自智能手机加速度计X轴的加速度信号,标准重力单位为“g”。每行显示一个128值的向量。 “ToothAcxxxSuff.txt”和“ToothAcAccZZReal.Txt”文件对应与Y轴和Z轴的数据。
(3)“'train/Inertial Signals/body_acc_x_train.txt'”:从总加速度中减去重力得到的加速度信号。
(4)“train/Inertial Signals/body_gyro_x_train.txt”:陀螺仪中每个窗口样本测量的角速度矢量。单位是弧度/秒。
行为数据分析
在应用前,对训练和测试数据进行统计分析,结果如下图所示。左图中显示的是训练样本中各个行为的数量统计,根据柱状图可以看出,各个行为数量基本均衡,没有特别多或者特别少。因此,数据不需要做其它处理。右图测试样本的行为数量统计,6个行为数据也是平衡的,适合各个行为的预测评估。
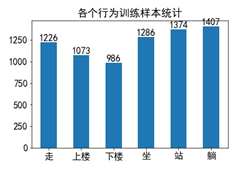
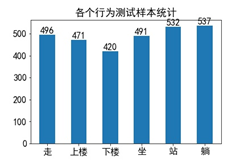
(a)训练集中的行为数据统计 (b) 测试集中的行为数据统计
应用卷积神经网络
任务1:使用卷积神经网络CNN进行行为识别。
步骤一:读取训练数据,参考代码如下:
| import pandas as pd |
步骤二:设置参数,参考代码如下:
| conv_size1 = 64 # 第一次卷积得到特征图个数 |
步骤三:定义模型,并使用上述获得的数据进行训练,参考代码如下:
| from keras.models import Sequential |
训练过程数据显示如下:

最终显示,精确率约为90.53%。
步骤四:使用测试数据对模型评估,参考代码如下:
| scores = model.evaluate(X_test,Y_test) |
运行结果显示如下:
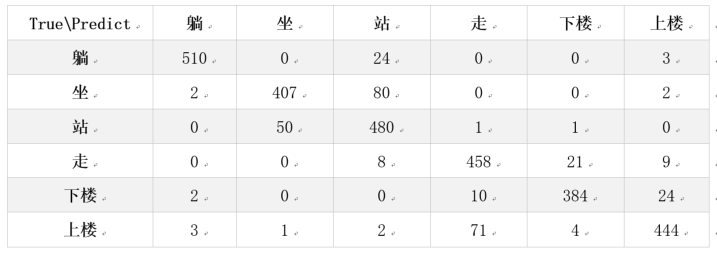
用测试数据进行模型评估,其预测准确率约为90.53%。此外,我们还可以使用混淆矩阵来查看具体的结果,参考代码如下:
| predicts = model.predict(X_test) |
具体预测结果如下表所示。
模型应用:Keras训练得到的模型,可以直接导出应用于APP。

