
第七章 协方差分析
学习要求: 掌握协方差分析的原理和方法,协方差分析的意义与作用;了解其分析的注意事项及应用条件;能够进行单因素实验资料的协方差分析。 |
当定量因素对观测结果的影响难以控制时,即使存在相互作用,使用协方差分析,这些影响变量称为协方差,减去(或消除)协方差的影响,可以得到修正的平均值估计。
协方差分析是一种将方差分析与回归分析相结合的统计分析方法。它用于比较一个或多个因素在不同层次上的变量y差异,但Y受这些因素影响,但也受另一个变量x的影响,且X变量的值难以人为控制,可以不能作为方差分析处理的一个因素。如果x与Y之间存在回归关系,则可以采用协方差分析的方法排除x对Y的影响,然后用方差分析的方法对各因子水平的影响进行统计推断。在协方差分析中,我们称y为因变量,x为协方差。
第一节 协方差分析概述
协方差分析(analysis ofcovariance)也称协方差协方差分析(analysis of variance with covariates),是一种结合回归分析和方差分析的分析方法。在各种实验设计中,主要变量y经常被认为与可能影响和干扰Y以使其达到平衡或可比性的其他变量一致,从而可以最小化测试误差的估计,从而实验准确获得加工因素的影响。然而,有时候,这些变量很难控制或根本无法控制。这些变量的值需要在实验中同时记录下来,这些变量被认为是独立变量或协变量(协变量),以建立变量y与协变量的回归方程,以便回归分析可以用于推导变量y中影响协方差的因素,因此比较不同层次定性因素的影响因子可能更为合理,回归分析意味着修正因变量的总体均值显著不同。简而言之,协方差分析是减去协方差的影响,或者将这些协方差作为平等来处理,然后分析修正的Y的平均值。
一、协方差分析的假定
协方差分析需要满足的假定为:
①各样本来自具有相同方差![]() 的正态分布总体,即要求各组方差齐性。
的正态分布总体,即要求各组方差齐性。
②协变量与主要变量y间的总体回归系数不等于0。
③各组的回归线平等,即回归系数![]() 。
。
如果上述的假定满足,就作协方差分析。前述的各种实验设计,如完全随机化设计、随机区组设计、析因设计、拉丁方设计等,都可以带一个或多个协变量,按设计方案扣除协变量的影响后,对主要变量y的修正均值作比较,得出统计结论。
二、协方差分析的模型
最简单的单因素一元协方差分析的模型,是由单因素效应模型![]() 加上协变量的影响因素
加上协变量的影响因素![]() 而得出:
而得出:
![]() (7-1)
(7-1)
其中![]() 为协变量,
为协变量,![]() 为协变量在分类水平i和j上的记录值,
为协变量在分类水平i和j上的记录值,![]() 为所有协变量的平均值,
为所有协变量的平均值,![]() 为相关的回归系数。设
为相关的回归系数。设![]() ,为平均截距。上式可以化简成
,为平均截距。上式可以化简成
![]() (7-2)
(7-2)
设![]() ,上式可以化简成
,上式可以化简成
![]() (7-3)
(7-3)
很明显![]() 是第i组回归线的截距,等于回归线的平均截距
是第i组回归线的截距,等于回归线的平均截距![]() 加上本组的效应
加上本组的效应![]() 。这个式揭示了,观察值
。这个式揭示了,观察值![]() 的模型可以表示成一组相似的回归线,且各组具有共同的回归系数
的模型可以表示成一组相似的回归线,且各组具有共同的回归系数![]() ,和各组自己的截距
,和各组自己的截距![]() 。
。
协方差分析有二个意义,一是对实验进行统计控制,二是对协方差组分进行估计,现分述如下。
一、对实验进行统计控制
为了提高测试的准确性和准确性,有必要采取有效措施来控制除治疗以外的所有条件,以使它们在处理之间尽可能保持一致,这就是所谓的测试控制。然而,在某些情况下,甚至付出巨大的努力都难以实现预期控制的目标。例如:研究几种饲料对仔猪增重效果的影响,我希望实验仔猪的初始体重一样,因为仔猪的初始体重不同,会影响仔猪的体重。结果表明,体重增加和初始体重之间存在线性回归。然而,在实际实验中难以满足仔猪初始体重的要求。这时可以使用仔猪的初始体重(记为x)和其体重增加量(记为y)的回归关系,仔猪的体重会按体重增加时的原始体重进行修正,所以初始体重对消除仔猪重量的影响不同。由于修正后的增重是基于统计方法的,因此初始权重控制是一致的,所以称之为统计控制。统计控制是测试控制的辅助手段。经过该校正后,测试误差将会降低,并且测试处理效果估计会更加准确。如果Y的变化主要是由X的差异引起的(治疗没有显著影响),修正之间没有显著差异(但是原始y的差异可能是显著的)。如果y的变化消除了x的不同影响,治疗方法存在显著差异,但两者之间存在显著差异(但是原始y的差异可能不明显)。另外,修正的和原始的y数量级往往不一致。因此,平均值的回归校正和校正均值的显著性检验可以提高测试的准确性和精度,从而更真实地反映实际的实验。
二、估计协方差组分
两个相关变量线性相关性质与程度的相关系数的计算公式:
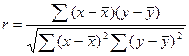
若将公式右端的分子分母同除以自由度(n-1),得
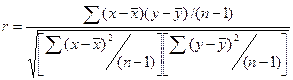 (7-4)
(7-4)
其中
![]() 是x的均方MSx,它是x的方差
是x的均方MSx,它是x的方差![]() 的无偏估计量;
的无偏估计量;
![]() 是y的均方MSy,它是y的方差
是y的均方MSy,它是y的方差![]() 的无偏估计量;
的无偏估计量;
![]() 称为x与y的平均的离均差的乘积和,简称均积,记为MPxy,即
称为x与y的平均的离均差的乘积和,简称均积,记为MPxy,即
MPxy=![]() =
=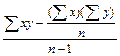 (7-5)
(7-5)
与均积相应的总体参数叫协方差(covariance),记为COV(x,y)或![]() 。统计学证明了,均积MPxy是总体协方差COV(x,y)的无偏估计量,即 EMPxy= COV(x,y)。
。统计学证明了,均积MPxy是总体协方差COV(x,y)的无偏估计量,即 EMPxy= COV(x,y)。
于是,样本相关系数r可用均方MSx、MSy,均积MPxy表示为:
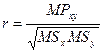 (7-6)
(7-6)
相应的总体相关系数![]() 可用x与y的总体标准差
可用x与y的总体标准差![]() 、
、![]() ,总体协方差COV(x,y)或
,总体协方差COV(x,y)或![]() 表示如下:
表示如下:
![]() (7-7)
(7-7)
均方具有相似的形式和相似的属性。在方差分析中,变量源的总平方和和自由度可以根据变化源进行划分,从而得到相应的均方。统计证明,两个变量的总产品和自由度也可以根据变异来源进行划分,得到相应的平均产品。将这两个变量的总产品与根据变化源的自由度相结合并获得相应平均产品的这种方法也被称为协方差分析。
在随机模型的方差分析中,可以根据均方根与期望均方根EMS之间的关系,得到不同变异源方差分量的估计。同样,在随机模型的协方差分析中,可以根据平均乘积MP与期望的均值 - 正交函数之间的关系来获得不同方差源的协方差分量的估计。通过这些估计,可以进行相应的整体相关分析。这些分析在遗传学,育种以及生态和环境研究中很有用。
有人会问,随机因素的影响也不是人为控制的,为什么不把X作为随机因素来处理呢?这里的主要区别在于,虽然每个级别的影响都不是由于随机因素而被人为控制的,但我们至少可以在同一级别重复多次,以便可以分别处理不同级别的另一个因素。最后,在方差分析中,我们可以消除这个随机因素的影响,并比较另一个因素的水平。这可以从以下计算公式中看出:
![]()
![]()
在上述公式中,如果第一个下标 i变化时相同的j所代表的第二个因素的水平都不相同,就没有理由认为下面的(7-8)式一定会成立,也就不能认为SSA仅是第一个因素的影响了。对于系统分组的方差分析,虽然不同的i中同一个j的取值可以不同,但仍要求
![]() (7-8)
(7-8)
这样就保证了在![]() 中可以消去第二个因素的影响。如果我们对第二个因素的取值完全无法控制,那就意味着对于不同的 i,βj的变化是完全没有规律的,当然也就不可能满足上述的(7-8)式,此时就没有办法采用方差分析的方法,只能把第二个因素视为另一个变量X,试试用协方差分析的方法排除它的影响了。
中可以消去第二个因素的影响。如果我们对第二个因素的取值完全无法控制,那就意味着对于不同的 i,βj的变化是完全没有规律的,当然也就不可能满足上述的(7-8)式,此时就没有办法采用方差分析的方法,只能把第二个因素视为另一个变量X,试试用协方差分析的方法排除它的影响了。
例如,当我们考虑动物巢穴对体重增加的影响时,一般来说,我们可以将其视为一个随机因子,这是因为它不容易量化,另一方面,同一巢穴通常有几只动物,可以接受另一个不同层次的治疗因素;如果我们在实验开始前考虑动物初始体重的影响,此时一般方法是分别选择同一动物的原始体重作为一组,分别接受另一个不同等级的治疗因素,此时与方差分析是没有问题的。但是如果有很少的动物需要进行实验,初始体重和存在显著差异,不能选择相同体重的动物,有必要认为初始体重x和最终体重y具有回归关系,使用协方差分析法消除初始体重的影响,然后比较其他因素,如饲料种类,体重增加量的影响。
消除初始重量影响的另一种方法是统计分析最终重量与初始重量之间的差异,即y-x。这种方法的生物学意义不同于协方差分析。对差异的分析假定初始重量对未来的体重增加没有任何影响,并且协方差分析假定最终重量包含效果的初始重量,该效果与初始重量成比例。如果此比率为1,则协方差分析与差异值的方差分析相同。但是如果比例不是1,他们的结果将会不同。换句话说,假设协方差分析使得不同因素在未来增长过程中的初始权重也会起作用,并且方差分析之间的差异被假设为这些因素不再起作用;这两种生物假说明显不同。我希望学生在学习统计学方法时不仅要注意它与其他算法的方法不同,还要注意算法背后的生物假说有什么不同,这种深刻的理解将有助于我们在未来的工作中选择正确的统计方法。
由于协方差分析过程包括一系列统计检验和估计协方差影响的存在和大小,因此它显然比差异分析更广泛适用,因此除非有明显的证据表明分析的生物学假设的差异是正确的,一般应该使用协方差分析法。
协方差分析的计算非常复杂。在本章中,我们将重点放在最简单的协方差分析算法上,即协方差单因素协方差分析。

