
第三节 多因素方差分析
在前一节中,我们讨论了最简单的方差分析-单因素方差分析的原理和方法。在实践中,问题往往很复杂,要求我们考虑两个或更多因素以及这些因素的影响。此时,单因素方差分析无法做到,需要采用两因素或多因素方差分析。多元方差分析的理论并没有困难,但随着素数的增加,常用方差分析的复杂度迅速增加,这不仅显示了分析和计算的复杂性,而且还显示了所需实验次数的增加。因此,当因素数量增加到三或三个以上时,工作量的大小往往令人望而生畏。因此,三或三因素的方差分析较少使用;当真正有必要考虑如此多的因素时,我们经常转而使用一些特殊的方差分析方法。基于上述原因,本节的内容将集中在双因素方差分析上。
一、模型类型及交互作用概念。
相互作用是多因素方差分析与单因素方差分析相比的新概念之一。当一个因素的影响明显取决于其他因素的水平时,我们称这些因素具有交互作用。例如,由于人体的不同,药物的疗效可能不同,同一种肥料的不同应用,产量效应不同,等等。交互式效果的可用性可以通过一些直观的方法粗略估计,例如可用图形估计:
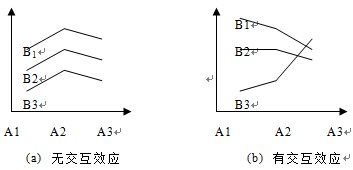
图6-1 交互效应示意图
图中的每条曲线都表示因子B的水平。如果曲线平行或近似平行,则不存在相互作用效应,否则存在相互作用效应。以上只是一种直观的判断,在多元方差分析过程中,我们也可以进行相互作用的统计检验。下面的文章详细介绍了具体的原理和方法。
多因素方差分析根据不同的标准可以分为不同的类别,不同的类别需要采用不同的分析方法。因此,有必要在分析多元方差之前正确判断问题的类型,否则可以使用误差分析方法。
按因子分类,多因素方差分析可分为固定模型、随机模型和混合模型。这些类型的模型基本上都是相同的公式,但他们的数学模型、假设、统计数据,对结果的解释有相当大的差异,我们将在下一篇文章中详细说明,使用时应根据实际情况予以考虑情况来选择合适的模型。
根据实验设计分类,多元方差分析可以分为两大类:交叉分组和系统分组。这两个公式之间也存在一些差异,我们以双因素方差分析为例介绍其实验设计的差异。
交叉分组:在实验中,一个因子的每个水平都满足因子B的每个水平,
所以A,B的地位是完全对称的。这是最常见的实验设计方法。
系统分组:先按A因素的a个水平分为a组,在每一组内再按B的水平
细分。一般A因素不同水平的组内B因素的水平可取不同值。例如研究PH值对酶活性的影响,不同的酶可能有不同的最适PH值,因此应对每种酶设置PH值偏高、合适、偏低三个水平,而不同的酶(因素A的不同水平)PH值(因素B)的水平可能是不相同的。
从上面可以看出,这两种方法适用于不同的问题,所以我们必须在实验设计阶段选择合适的方法才能得到正确的结果。他们的计算方法和公式是不同的。应该注意使用。以下是各种分析方法的详细说明。
二、两因素交叉分组方差分析
(1)固定效应模型首先考虑有重复的情况。线性统计模型为:
![]()
其中 ![]() :总平均值;
:总平均值;![]() :A因素
:A因素![]() 水平主效应;
水平主效应;![]() :B因素
:B因素![]() 水平主效应;
水平主效应;![]() :A因素
:A因素![]() 水平与B因素
水平与B因素![]() 水平的交互效应;
水平的交互效应;![]() :随机误差。
:随机误差。
对固定效应模型,应有:
![]() ,
, ![]() ,
, ![]()
![]()
零假设为:
![]()
![]()
![]()
备择假设为:
![]() 上述各参数中至少有一个不为0。(这实际上是三个备择假设)
上述各参数中至少有一个不为0。(这实际上是三个备择假设)
方差分析的基本思想仍是总变差分解:
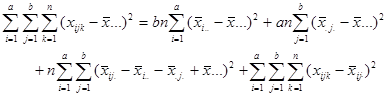
即:![]()
自由度分别为:![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]()
均方数学期望分别为:
![]()
![]()
![]()
![]()
上述![]() ,
,![]() 的均方期望中均不含有交互作用项,这是因为对固定模型来说,交互作用满足:
的均方期望中均不含有交互作用项,这是因为对固定模型来说,交互作用满足:
![]()
这说明观测值![]() 只要对
只要对![]() 或
或![]() 中的一个下标求和或求平均,就可以保证交叉项为0。
中的一个下标求和或求平均,就可以保证交叉项为0。
由于 ![]() ,
,![]()
公式中的![]() 均为平均数,因此上述条件实际保证了在它们的均方期望中不会含有交互作用项。这样,检验两个主效应及一个交互效应的下述三个统计量中,分母全部采用
均为平均数,因此上述条件实际保证了在它们的均方期望中不会含有交互作用项。这样,检验两个主效应及一个交互效应的下述三个统计量中,分母全部采用![]() 即可。
即可。
检验![]() ,
,![]() ,
,![]() 的统计量分别为:
的统计量分别为:
![]() (6-23)
(6-23)
![]() , (6-24)
, (6-24)
![]() (6-25)
(6-25)
从前述的各均方期望可知,只有当各![]() 成立时,上述三个分子才是
成立时,上述三个分子才是![]() 的无偏估计量,此时各统计量均服从
的无偏估计量,此时各统计量均服从![]() 分布;若某个
分布;若某个![]() 不成立,则相应的分子将有偏大的趋势,从而使对应的统计量也有偏大的趋势,因此可用
不成立,则相应的分子将有偏大的趋势,从而使对应的统计量也有偏大的趋势,因此可用![]() 分布上单尾分位数进行检验。
分布上单尾分位数进行检验。
各效应的估计值为:
![]()
![]()
![]()
其中![]() ,
,![]() 。
。
实际计算公式为:
![]() (6-26)
(6-26)
![]() (6-27)
(6-27)
![]() (6-28)
(6-28)
![]() (6-29)
(6-29)
![]()
或计算:
![]() , (6-30)
, (6-30)
则:
![]()
可按以下步骤计算:
(1)计算![]() 排列如下表:
排列如下表:
j i |
1 2 …… b |
|
1 2a |
|
|
|
|
表中最下一行是各列的平均,最右一列是各行的平均。
(2)把所有原始数据放在一起,计算样本方差![]() ,则
,则
![]() (6-31)
(6-31)
(3)用上表中![]() 计算样本方差
计算样本方差![]() ,则
,则
![]() (6-32)
(6-32)
(4)用上表中![]() 计算样本方差
计算样本方差![]() ,则
,则
![]() (6-33)
(6-33)
(5)用上表中![]() 计算样本方差
计算样本方差![]() ,则
,则
![]() (6-34)
(6-34)
(6)
![]() , (6-35)
, (6-35)
![]() (6-36)
(6-36)
计算上述结果后,再根据各![]() 统计量的自由度查出其
统计量的自由度查出其![]() 及
及![]() 分位数,并将
分位数,并将![]() 计算值与相应分位数相比,大于
计算值与相应分位数相比,大于![]() 则在统计量
则在统计量![]() 右上角标一个“*”号;大于
右上角标一个“*”号;大于![]() 则再加一个“*”号。最后用一句话对上述方差分析的结果加以总结,即哪些主效应或交互效应达到显著或极显著水平,哪些不显著。
则再加一个“*”号。最后用一句话对上述方差分析的结果加以总结,即哪些主效应或交互效应达到显著或极显著水平,哪些不显著。
如果![]() 小于或约等于
小于或约等于![]() ,即
,即![]() 小于或约等于1,说明此时交互作用不存在,在这种情况下也可把
小于或约等于1,说明此时交互作用不存在,在这种情况下也可把![]() 和
和![]() 合并在一起(即把平方和和自由度都合并)作为
合并在一起(即把平方和和自由度都合并)作为![]() 的估计量,这样可以提高检验的精确度。具体计算公式如下:
的估计量,这样可以提高检验的精确度。具体计算公式如下:
![]() (6-37)
(6-37)
然后可用![]() 作统计量
作统计量![]() 和
和![]() 的分母,对两个主效应进行统计检验(见例题4.7)。注意查表时分母自由度要相应改变。
的分母,对两个主效应进行统计检验(见例题4.7)。注意查表时分母自由度要相应改变。
例6.3为选择最适发酵条件,用三种原料、三种温度进行了实验,得结果如表6-7。请进行统计分析。
表6-7 不同条件下发酵的酒精产量
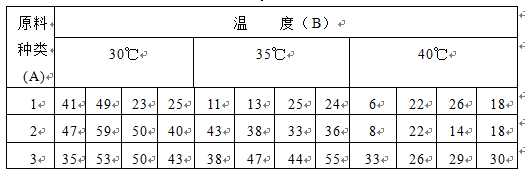
解:本题中显然温度是一个因素,原料种类是另一个因素。这两个因素各有三个水平。由于它们的影响都是可控制、可重复的,因此都是固定因素。在同样温度、原料下所做的几次实验应视为重复,它们之间的差异是由随机误差所造成的。具体计算过程如下:
首先计算各处理的平均数,填入下表:
表6-8 各处理平均数![]() 表
表
j i |
1 |
2 |
3 |
|
1 |
34.5 |
18.25 |
18 |
23.58 |
2 |
49 |
37.5 |
15.5 |
34 |
3 |
45.25 |
46 |
27 |
39.42 |
|
42.92 |
33.92 |
20.12 |
根据(6-31)-(6-36)式,有:
样本方差![]() = 204.8571,
= 204.8571,![]() =(36-1)×
=(36-1)×![]() = 7170.00
= 7170.00
把表6-8中间部分9个![]() 输入带入公式,得样本方差
输入带入公式,得样本方差![]() =172.2969,
=172.2969,![]() =
= ![]() = 4×(3×3-1) ×172.2969 = 5513.50
= 4×(3×3-1) ×172.2969 = 5513.50
把表6-8中各![]() 带入,得样本方差
带入,得样本方差![]() = 64.7575,
= 64.7575,![]() =
= ![]() = 3×4×(3-1)×64.7575 =1554.18
= 3×4×(3-1)×64.7575 =1554.18
把表6-8中各![]() 带入,得
带入,得![]() =131.2708,
=131.2708,![]() =
= ![]() = 3×4×(3-1)×131.2708 = 3150.50
= 3×4×(3-1)×131.2708 = 3150.50
![]()
![]()
列成方差分析表,得:
表6-9 发酵实验方差分析表
变差来源 |
平方和 |
自由度 |
均方 |
F |
原料A 温度B AB 误差 |
1554.18 3150.50 808.82 1656.50 |
2 2 4 27 |
777.09 1575.25 202.21 61.35 |
12.67** 25.68** 3.30* |
总和 |
7170.00 |
35 |
查![]() 分布表,得:
分布表,得:
F0.95(2,27)≈F0.95(2,30)=3.316,F0.99(2,27)≈F0.99(2,30)=5.390,
F0.95(4,27)≈F0.95(4,30)=2.690,F0.99(4,27)≈F0.99(4,30)=4.018,
∴FA,FB均达极显著,标上“* *”,FAB只达显著,标上“*”。因此酒精产量不仅与原料和温度的关系极显著,与它们的交互作用也有显著关系。即对不同原料应选用不同的发酵温度。
在固定效应模型中,若各F统计量有达到显著或极显著水平时,常常还需要在各处理间进行多重比较,以选出所需要的条件组合。例如在例6.3中,我们已经发现原料,温度以及它们的交互作用都对酒精的产量有影响,显然我们应进一步找出最优的条件组合以用于生产。这就需要进行多重比较了。如果没有交互作用,可以固定B因素的一个水平,例如取j=1,比较A因素各水平的平均数![]() ,得到最优值i*。再固定i,例如仍取为1,比较B因素各水平均值
,得到最优值i*。再固定i,例如仍取为1,比较B因素各水平均值![]() ,得到最优值j*。则条件组合A因素i*水平,B因素j*水平就应是所有参加实验的水平组合中最优的。如果有交互作用存在,则一般需要把所有ab个水平组合放在一起比。比较的方法仍与单因素方差分析相同,最常用Duncan法。
,得到最优值j*。则条件组合A因素i*水平,B因素j*水平就应是所有参加实验的水平组合中最优的。如果有交互作用存在,则一般需要把所有ab个水平组合放在一起比。比较的方法仍与单因素方差分析相同,最常用Duncan法。
例6.4 对例6.3中各处理作多重比较。
解:把各处理平均数从大到小排列(记为x1-x9):
49, 46,45.25, 37.5, 34.5, 27, 18.25, 18, 15.5
求出各对差值,列成下表:
x9 |
x8 |
x7 |
x6 |
x5 |
x4 |
x3 |
x2 | |
x1 x2 x3 x4 x5 x6 x7 x8 |
33.5** 30.5** 29.75** 22** 19** 11.5 2.75 2.5 |
31** 28** 27.25** 19.5** 16.5** 9 0.25 |
30.75** 27.75** 27** 19.25** 16.25** 8.75 |
22** 19** 18.25** 10.5 7.5 |
14.5* 11.5 10.75 3 |
11.5 8.5 7.75 |
3.75 0.75 |
3 |
根据公式(6-20),求得:
![]() ,df=27
,df=27
查Duncan检验的r值表,求出df=27, k=2-9,α=0.05和α=0.01的r值,并求出临界值R=r![]() ,列成下表:
,列成下表:
K |
r0.05 |
R0.05 |
r0.01 |
R0.01 |
2 3 4 5 6 7 8 9 |
2.91 3.05 3.14 3.21 3.27 3.30 3.34 3.36 |
11.40 11.94 12.30 12.57 12.81 12.92 13.08 13.16 |
3.92 4.10 4.20 4.29 4.35 4.40 4.45 4.49 |
15.35 16.06 16.45 16.80 17.04 17.23 17.43 17.58 |
将差值表中的数与临界值比较,超过R0.05的标一个“*”号,超过R0.01的标“**”号,一次可核对一条对角线(从左下到右上),因为它们有共同的k值。在第一条最长的对角线上,k=2;其左上相邻的一条k=3;余类推,直到左上角最后一个数字,在本题中它的k应取为9。
分析:从这一差值表中可见,x1至x5,除x1至x5外相互间都没有显著差异。但x4,x5与其他3个值差异相对大一些。x6至x9差异均不显著。而x1,x2,x3与x6-x9差异均达极显著。另外,x1,x2,x3以及x7,x8,x9之间的差异都很小。由于现在的数据是发酵产量,显然是越高越好,因此我们主要关心x1,x2,x3。从以上分析中可知,基本上可把x1,x2,x3视为无差异,可在这三组条件组合中,进一步考虑原料成本,原料来源稳定性等其他条件,选一组投入生产。也可对这三组条件增加重复数,进一步检验它们间是否仍有差异。如果实际问题不是要求选最大的数,而是选最小的数,那么根据类似的分析,我们应在x7,x8,x9对应的三组数中选择。
总之,多重比较的结果分析比较复杂,也比较灵活,需要结合具体数据以及实际问题的要求来进行。这一点请同学们务必注意。
几点注意事项:
1°当交互作用存在时,对固定模型若不设置重复,则无法把SSAB与SSe分开,这样将无法进行任何统计检验。因此在固定模型中有交互作用时,不设置重复的实验是无意义时。
2°对固定模型来说,结论只能适用于参加实验的几个水平,不能任意推广到其他水平上去。
1.无重复的情况:
我们刚刚强调了固定模型中方差分析中重复的重要性,但重复对所有方差的分析很重要,我们将在后面提及。但是重复次数每增加1次,整个过程就必须再次完成一次,工作量的成本将会很大。因此,如果经验或专业知识可以确定两个因素不相互作用,则不能设置重复,这可以大大减少工作量。
此时线性统计模型变为:
![]() i=1,2,…a, j=1,2, …b
i=1,2,…a, j=1,2, …b
其中![]()
零假设:![]()
![]()
均方数学期望:
![]()
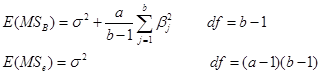
统计量:
![]()
其他如结果的解释,计算公式等均与以前一样,只是令n=1即可。
例6.5 在1976-1979四年间四个生产队的小麦亩产量如表6-10所示。各年,各生产队产量是否有显著差异?
表6-10 四个生产队四年小麦田产量(斤)
| 年 度(A) | 平均( | |||||
| 1976 | 1977 | 1978 | 1979 | |||
| 队 别 (B) | 1 | 546 | 578 | 813 | 815 | 688 |
| 2 | 600 | 703 | 861 | 854 | 754.5 | |
| 3 | 548 | 682 | 815 | 852 | 724.25 | |
| 4 | 551 | 690 | 831 | 853 | 731.25 | |
| 平均 | 561.25 | 663.25 | 830 | 843.5 | 724.5 | |
解:这个问题显然是两个因素,没有重复的方差分析。一个因素是生产团队和年份。由于生产队对产量的影响主要体现在土地肥力,灌溉质量,耕作习性等方面,可以认为在几年内是稳定的,因此可以看作是一个固定的因素,而影响产量的年份主要体现在气候上,这是不可重复的,所以它应该被视为一个随机因素。因此,主体实际上变成了双因素混合模型的方差分析。但是因为没有互动效应(这最好由专家来判断,但在这种情况下,专业知识难以确定不同类型的气候是否对生产团队产生一致的影响,所以我们假设这种互动不存在,然后提供一个实验方法,统计计算和实验方法变得与固定模型相同,最终结果的解释只有不同,即固定因子的结果不能延伸到其他层次,随机因素的结果可以扩展到其他层次,这些差异的原因在随机和混合模型中有详细描述。
计算得:![]()
![]()
由![]() ,得
,得![]()
![]()
由![]() ,得
,得![]()
![]()
列成方差分析表:
变差来源 |
平方和 |
自由度 |
均方 |
F |
队别 年度 误差 |
9111.5 222773.5 5379.0 |
3 3 9 |
3037.17 74257.83 597.667 |
5.082* 124.246** |
总和 |
237264.0 |
15 |
查F分布表,得:F0.95(3,9)=3.863,F0.99(3,9)=6.992,所以,FA达显著,FB达极显著,分别标以“*”和“**”。即,生产队间产量差异显著,年度间差异极显著。
2.两因素无重复模型中交互效应的检验
若由于某种原因不能安排重复,但对是否有交互效应又没有十分把握,则可采用Tukey于1949年提出的一种方法作判断。方法是把残余项(SST-SSA-SSB)再分解,得:
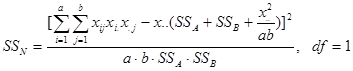 (6-38)
(6-38)
![]() (6-39)
(6-39)
令![]() 若有交互作用,F有偏大的趋势。所以可用上单尾分位数进行检验。
若有交互作用,F有偏大的趋势。所以可用上单尾分位数进行检验。
例6.6 判断例6.5中队别与年度间是否有交互作用。
解:![]()
![]()
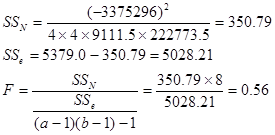
查表,F0.95(1, 8) = 5.32,所以接受![]() ,可以认为无交互作用。
,可以认为无交互作用。
需要注意的是上述方法虽理论上可行,但在实用中却有很大问题。从(6-38)式可知,![]() 的分子实际是两大串数字分别相乘相加再相减,然后再平方。这个计算公式从错误传输的角度来看,这是一个很大的禁忌。因为按照错误传递的理论,此外,乘法过程中,有效数(即不受错误影响,可以信任的数)不会增加,并且会集中在前几个0位。在下一个减法中,非零数字的最大数目通常是相同的,并且减号变为0,所以有效数字通常大大减少。在例6.6中,前4位有效数字丢失,并且在一般实验中测得的有效位数很少达到4位数。从这个角度来看,这种实验方法非常不可靠。以上计算只能被视为计算方法的一个例子。
的分子实际是两大串数字分别相乘相加再相减,然后再平方。这个计算公式从错误传输的角度来看,这是一个很大的禁忌。因为按照错误传递的理论,此外,乘法过程中,有效数(即不受错误影响,可以信任的数)不会增加,并且会集中在前几个0位。在下一个减法中,非零数字的最大数目通常是相同的,并且减号变为0,所以有效数字通常大大减少。在例6.6中,前4位有效数字丢失,并且在一般实验中测得的有效位数很少达到4位数。从这个角度来看,这种实验方法非常不可靠。以上计算只能被视为计算方法的一个例子。
综合分析,我们可以得出以下结论:
1°在可能的情况下不采用无重复方差分析;
2°如果必须采用,最好由专业知识保证交互作用不存在;
3°终于没有办法使用Tukey方法进行统计实验,此时应注意计算过程中的有效位数,尽量保证结果的可靠性。
3.无重复方差分析中缺失数据的弥补
事先根据实验设计收集方差分析数据。但是有时一些或两个实验数据可能由于一些意想不到的原因而丢失,例如不可抗拒的自然灾害,实验动物的死亡,操作错误等。当然,最好的方法是重做相关实验来补充,但这有时是不可能的。例如,农作物不能种植农作物,明年气候条件发生变化,无法比拟等等。在这一点上放弃整个实验将是一个遗憾,所以我们需要某种补救措施。
对于重复的差异分析,只要一次或两次数据的丢失一般不会成为问题,只要不改变处理方式。对于没有重复的实验设计,必须弥补丢失的数据。常用的方法是根据最小化误差平方的原则来估计丢失的数据。以下是没有重复差异分析的两个因素的示例。
设缺失的数据为![]() ,把它代入
,把它代入![]() 的计算公式:
的计算公式:
![]()
![]()
根据最小二乘法,使![]() 最小的
最小的![]() 应满足:
应满足:![]() 0
0
若用![]() ,
,![]() ,
,![]() 分别代表去掉未知的
分别代表去掉未知的![]() 后的各有关和数,则上式变为:
后的各有关和数,则上式变为:
![]()
可解得:
![]() (6-40)
(6-40)
上述公式也可从另一思路获得,由线性统计模型有:
![]()
其中![]() ,
,![]() ,
,![]() 的估计值分别为:
的估计值分别为:
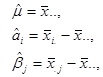
代入线性统计模型,可得![]() 的估计值为:
的估计值为:
![]()
仍用![]() ,
,![]() ,
,![]() 分别代表去掉未知的
分别代表去掉未知的![]() 后的各有关和数,则可得:
后的各有关和数,则可得:
![]()
这与根据最小二乘法得到的方程是完全一样的,解当然也相同。
若丢失两个数据![]() ,
,![]() 仍可采用最小二乘法,令
仍可采用最小二乘法,令
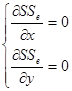
解上述方程组即可得到![]() ,
,![]() 的估计值。也可采用迭代法:令
的估计值。也可采用迭代法:令![]() ,代入(6-40)式,可求出
,代入(6-40)式,可求出![]() ,再把
,再把![]() 代入(6-40)式,求出
代入(6-40)式,求出![]() …,这样反复迭代,直到
…,这样反复迭代,直到![]() 与
与![]() 和
和![]() 与
与![]() 的差很小为止。
的差很小为止。
几点说明:
1°缺失数据估计出以后,把它填入相应的位置,按一般方差分析的方法计算即可。但自由度会有变化,总自由度应减去缺失的数据个数,![]() 、
、![]() 的自由度不变,误差项自由度也相应减小。
的自由度不变,误差项自由度也相应减小。
2°缺失数据的估计只是一个技术过程,可以进行计算。但是原始的实验数据应该由无法找到的信息提供回来。因此,如果缺少更多的数据,我们必须取消所有的结果,而不情愿的分析会得出错误的结论。所以,实验一定要认真,尽量不要丢失数据,不能依靠计算方法来弥补。
3°的原理是使误差平方和最小,以便平方和的处理具有大的趋势。这相当于引入了一个额外的错误,降低了结论的可靠性。如果缺乏数据不多,整体实验结果没有太大影响,如果有更多的缺失数据,你应该放弃数据。
4°在方差分析中,不需要组合,只需使用不等重复的计算方法即可。
4.随机效应模型
与固定效应模型相比,线性统计模型本身无变化:
![]()
但主效应与交互效应变成了随机变量,它们应满足的条件变为:
![]()
因此观察值的方差变为:
![]()
零假设:
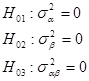
总变差的分解仍同固定模型一样,自由度也不变:
![]()
均方数学期望变为:
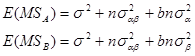
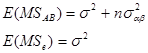
注意上述![]() ,
,![]() 的均方期望中,均含有交互作用项
的均方期望中,均含有交互作用项![]() ,这一点与固定模型是完全不同的。其原因就在于现在是随机模型,交互作用应满足的条件变为
,这一点与固定模型是完全不同的。其原因就在于现在是随机模型,交互作用应满足的条件变为![]() 。由于
。由于![]() 现在是随机变量,不再能保证
现在是随机变量,不再能保证![]() 。这样一来,
。这样一来,![]() ,
,![]() 表达式中
表达式中![]() 均不可能把交互作用项完全消掉,从而也就出现在它们的均方期望中。由于
均不可能把交互作用项完全消掉,从而也就出现在它们的均方期望中。由于![]() ,
,![]() 的均方期望含有交互作用项,检验主效应的统计量也就不能再用
的均方期望含有交互作用项,检验主效应的统计量也就不能再用![]() 做分母,而需要改用
做分母,而需要改用![]() 了。
了。
因此,检验各假设的统计量变为:
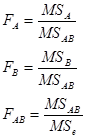
对检验结果的解释现在也不局限于参加实验的水平,而是可推广到一切水平上。
如果有必要的话,可以根据均方数学期望算出各方差的估计值:
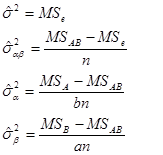
实际计算公式不变,不再重复。对于随机效应模型多重比较是无意义的,因为一般来说处理的效果是无法严格重复的。
与固定模型相同,若![]() 的值小于或约等于1,说明交互作用不存在,则可把
的值小于或约等于1,说明交互作用不存在,则可把![]() 与
与![]() 合并。合并方法也与固定模型相同,即为:
合并。合并方法也与固定模型相同,即为:
![]() (6-41)
(6-41)
然后用![]() 作分母构造统计量
作分母构造统计量![]() 与
与![]() 。注意查表时分母自由度也要变为
。注意查表时分母自由度也要变为![]() 。
。
5.混合模型:
不失一般性,我们可假设A因素是固定型,B因素是随机型。线性统计模型仍不变:
![]()
条件变为:
![]()
![]()
![]()
但各![]() 不是完全独立的,它满足:
不是完全独立的,它满足:
![]()
即在随机因素的任一水平上![]() 均不是独立的。
均不是独立的。
均方期望:
![]()
![]()
![]()
![]()
注意上述均方期望中,固定因素A的均方期望含有交互作用项![]() ,而随机因素B反而不含,这跟固定模型和随机模型正好是相反的。造成这种差异的原因还是在
,而随机因素B反而不含,这跟固定模型和随机模型正好是相反的。造成这种差异的原因还是在![]() 满足的条件上:对任意固定
满足的条件上:对任意固定![]() ,有:
,有:![]() ,而对固定的
,而对固定的![]() ,
,![]() 。这样一来,在
。这样一来,在![]() 的表达式中,
的表达式中,![]() 和
和![]() 都可保证交互作用被消除掉,从而
都可保证交互作用被消除掉,从而![]() 的均方期望中也就不会有
的均方期望中也就不会有![]() 项;但
项;但![]() 中的
中的![]() 却不能使
却不能使![]() 被彻底消去,从而均方期望中也就会出现
被彻底消去,从而均方期望中也就会出现![]() 项。这种均方期望的差异当然会反映在统计量中,即统计量相应变为:
项。这种均方期望的差异当然会反映在统计量中,即统计量相应变为:
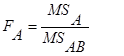
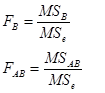
注意上述统计量中由于固定因素的均方期望中有![]() 项,要用
项,要用![]() 作
作![]() 统计量的分母;而随机因素的均方期望中没有
统计量的分母;而随机因素的均方期望中没有![]() 项,要用
项,要用![]() 作
作![]() 统计量的分母。这正是
统计量的分母。这正是![]() ,而
,而![]() 的结果。
的结果。
固定因素效应估计:
![]()
![]() , i=1,2,……a。
, i=1,2,……a。
方差分量的估计为:
![]()
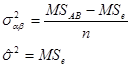
在结果解释方面,固定因素的结论只能适用于参加实验的几个水平,不能推广;而随机因素的结论可推广到它的一切水平上去。其他如变差分解,自由度分解,计算公式,![]() 小于或约等于1的处理等均不变,不再重复。
小于或约等于1的处理等均不变,不再重复。
例6.7 为检验三种配合饲料的效果,从三窝仔猪中各选9只,随机分成三组,分别喂以三种饲料。日增重值见表6-11,请对结果作统计分析。
表6-11 仔猪日均增重表
饲料 (A) |
窝 别 (B) | ||||||||
1 |
2 |
3 | |||||||
1
2
3 |
1.38 |
1.30 |
1.25 |
1.26 |
1.23 |
1.30 |
1.19 |
1.23 |
1.25 |
1.29 |
1.32 |
1.23 |
1.22 |
1.28 |
1.25 |
1.23 |
1.18 |
1.17 | |
1.35 |
1.40 |
1.36 |
1.32 |
1.28 |
1.35 |
1.27 |
1.31 |
1.26 | |
解:饲料是固定因素,窝别是随机因素,这是一个两因素交叉分组混合模型。首先把原始数据改写成以下的处理均值![]()
|
1 |
2 |
3 |
|
1 |
1.31 |
1.263 |
1.223 |
1.266 |
2 |
1.28 |
1.25 |
1.193 |
1.241 |
3 |
1.37 |
1.317 |
1.28 |
1.322 |
|
1.32 |
1.277 |
1.232 |
1.276 |
(1)由![]() ,算得它们的子样方差为
,算得它们的子样方差为![]() ,得:
,得:
![]() ;
;
(2)由![]() ,得其子样方差
,得其子样方差![]() ,得:
,得:
![]() ;
;
(3)由![]() ,得子样方差
,得子样方差![]() ,得:
,得:
![]()
(4)由各原始数据![]() ,得子样方差
,得子样方差![]() 得:
得:
![]()
(5)![]()
(6)![]()
(7)由于![]() ,各自由度分别为:
,各自由度分别为:
![]()
![]()
![]()
![]()
![]()
(8)把上述计算结果列成方差分析表:
变差来源 |
平方和 |
自由度 |
均方 |
F |
饲料(A) 窝别(B) AB 误差(e) |
0.03116 0.03467 0.00053 0.02626 |
2 2 4 18 |
0.01558 0.01734 0.000133 0.00146 |
117.1** 11.88** 0.091
|
总和 |
0.09264 |
26 |
查表,得:F0.95(2,4) = 6.94,F0.99(2,4) = 18.0
F0.95(2,18) = 3.55,F0.99(2,18) = 6.01
F0.95(4,18) = 2.93
由于FA =117.1 > F0.99(2, 4),因此A因素(饲料)主效应达极显著;
由于FB =11.83 > F0.99(2, 18),因此B因素(窝别)主效应也达极显著;
由于FAB =0.091 < F0.95(4, 18),因此交互效应不显著。
由于FAB<1,为提高检验精度,可将![]() 与
与![]() 合并:
合并:
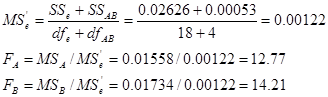
查表,得:F0.95(2,22) = 3.44,F0.99(2,22) = 5.72,
由于FA= 12.77 > F0.99(2,22),FB =14.21 > F0.99(2, 22),因此两因素(饮料与窝别)的主效应均达极显著水平。交互效应显然不显著。
几点注意事项:
1°由于![]() 一般要大于
一般要大于![]() ,尤其是交互作用存在时更是显著地偏大,因此若不注意区分是随机因素还是固定因素,就有可能错用统计量,导致错误的结论。因此在两个以上因素的方差分析中,区分因素类型显得更为重要。
,尤其是交互作用存在时更是显著地偏大,因此若不注意区分是随机因素还是固定因素,就有可能错用统计量,导致错误的结论。因此在两个以上因素的方差分析中,区分因素类型显得更为重要。
2°在随机模型和混和模型中若不设置重复,同样会导致无法把![]() 与
与![]() 分开。此时,主效应仍然可以通过随机模型来检验,并且可以在混合模型中实验固定因子的主要影响。但是当互动存在时,实验主效应并不重要,因为互动可能起着主要作用。只要条件允许,不管哪种类型的模型应该重复设置,除非有可靠的证据证明相互作用不存在。
分开。此时,主效应仍然可以通过随机模型来检验,并且可以在混合模型中实验固定因子的主要影响。但是当互动存在时,实验主效应并不重要,因为互动可能起着主要作用。只要条件允许,不管哪种类型的模型应该重复设置,除非有可靠的证据证明相互作用不存在。
三、两个以上因素的方差分析
两因素方差分析的方法在理论上已扩展到三个或三个以上的因素,但不仅相应的计算过程明显复杂,而且所需的实验总数也大大增加,所以一般使用较少。当考虑因素时,实验设计一般采用正交设计法,这样可以大大减少实验次数,分析起来更方便。本文以三因素交叉群固定效应模型为例给出其计算公式和方差分析表。
线性统计模型为:
![]()
其中![]() ,
,![]() ,
, ![]() ,
,![]() 。
。
总变差的分解为:
![]()
计算公式和自由度为:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
统计量及均方期望见表6-12。
表6-12三因素交叉分组固定效应方差分析表
变差 来源 |
平方和 |
自由度 |
均方数学期望 |
F |
A |
SSA |
a-1 |
|
|
B |
SSB |
b-1 |
|
|
C |
SSC |
c-1 |
|
|
AB |
SSAB |
(a-1)(b-1) |
|
|
BC |
SSBC |
(b-1)(c-1) |
|
|
AC |
SSAC |
(a-1)(c-1) |
|
|
ABC |
SSABC |
(a-1)(b-1)(c-1) |
|
|
误差 |
SSe |
Abc(n-1) |
| |
总和 |
SST |
Abcn-1 |

