
第二节 统计检验的基本步骤
概率分布不是研究人员从数据中看到的分布,我们讨论它不是出于数学爱好,而是因为统计推断的工作需要它。所有统计检验都包含特定步骤:
(1)建立适当的原假设和备择假设
根据研究问题的需要,提出了假设,包括原假设![]() 和备择假设
和备择假设![]() 。同时指出,该测试是双尾测试或左单尾或右尾测试。原假设必须包括等号,而备择假设是根据问题的性质选择≠ 、>、<,三者之一。统计检查是判断抽样结果和抽样分布的工作。描述性统计方法足以获得抽样结果。抽样分布不是,它不能从数据中获得,也不能使用概率论。如果不假设一般总体和采用的抽样程序,这项工作就不可能实现。
。同时指出,该测试是双尾测试或左单尾或右尾测试。原假设必须包括等号,而备择假设是根据问题的性质选择≠ 、>、<,三者之一。统计检查是判断抽样结果和抽样分布的工作。描述性统计方法足以获得抽样结果。抽样分布不是,它不能从数据中获得,也不能使用概率论。如果不假设一般总体和采用的抽样程序,这项工作就不可能实现。
(2)构造检验统计量(test statistic),求抽样分布
收集样本数据并计算测试统计的样本观察值。如果确定,则接受或拒绝的决定取决于统计数量。根据概率的含义来判断。此统计量的分布由多个因素决定,如样本平均值,样本百分比或样本方差,无论是大样本还是小样本,还是总体方面。在做出必要的假设之后,我们可以使用数学推理过程来查找抽样分布。由于数学已经实现,其实统计工作者做这个工作往往不是真的去寻求抽样分布的数学形式,而是根据具体需要,来确定统计检验的具体问题应该是用于数学表格。检验统计量是统计检验的重要工具,其功能是利用它来构造观测数据与预期数量之间的差异程度。分布在原假设下是完全已知的或可计算的。检验的名称由使用什么统计来命名。
(3)选择显著性水平和否定域(选择适当的显著性水平)
![]() 通常取5% 或1%,个别情况下使用0.1。
通常取5% 或1%,个别情况下使用0.1。![]() 的选择有很大任意性。选择的主要依据是犯了两类错误后的危害性大小。例如,若问题为药品出厂检验,
的选择有很大任意性。选择的主要依据是犯了两类错误后的危害性大小。例如,若问题为药品出厂检验,![]() :合格,
:合格,![]() :不合格。第一类错误为实际合格,判为不合格,药厂承受经济损失;第二类错误为实际不合格,判为合格,出厂后可能引起严重的索赔问题。权衡利弊,第二类错误危害大。因此应取较大的
:不合格。第一类错误为实际合格,判为不合格,药厂承受经济损失;第二类错误为实际不合格,判为合格,出厂后可能引起严重的索赔问题。权衡利弊,第二类错误危害大。因此应取较大的![]() ,以减小
,以减小![]() 。反之,若检验对象是钮扣,则即使有些废品率稍高的产品进入市场也不会有多大关系,而报废一批产品损失就很大,因此应减小
。反之,若检验对象是钮扣,则即使有些废品率稍高的产品进入市场也不会有多大关系,而报废一批产品损失就很大,因此应减小![]() 。
。
显著性水平是小概率水平,但小概率不同于不发生,只是发生的概率很小。如果我们接受原始假设是正确的,或者我们拒绝原假设是错误的,这表明我们做出了正确的决定。假设检验是围绕假定内容的验证进行的。如果我们接受原始假设是正确的,或者我们拒绝原始假设是错误的,这表明我们做出了正确的决定。但是,由于假设检验是基于样本提供的信息,因此可能会犯错误。有一种情况是,最初的假设是正确的,我们拒绝它是一个错误。犯下此类错误的概率在统计上表示为显著水平,也是统计决策的风险。多少是合适的取决于所犯错误的后果以及第二类错误![]() 和人们支付的费用。如果该值设定得非常小,则承担接受不真实原假设的较大概率的风险,而如果该值设定得非常大,则拒绝真正的原假设的风险有风险。因此,有必要根据问题的性质选择合适的一种。通过与问题相关的抽样分布,我们可以将所有可能的结果分为两类:一类不太可能;另一个预计会发生。既然如此,如果我们在实际样本中得到的结果恰好是第一类
和人们支付的费用。如果该值设定得非常小,则承担接受不真实原假设的较大概率的风险,而如果该值设定得非常大,则拒绝真正的原假设的风险有风险。因此,有必要根据问题的性质选择合适的一种。通过与问题相关的抽样分布,我们可以将所有可能的结果分为两类:一类不太可能;另一个预计会发生。既然如此,如果我们在实际样本中得到的结果恰好是第一类![]() ,我们有理由怀疑概率分布的假设。在统计检验中,这些不可能的结果被称为否定域。如果这样的结果确实发生,我们将否定这个假设;概率分布的具体形式由假设决定,并且必须有多于一个。值得注意的是,这个假设只能被测试,并且从未被证实。统计检验可以帮助我们否定假设,但它不能帮助我们确认一个假设。为了使检验更加严谨和科学,需要更多的东西。首先,我们必须确定冒犯第一类
,我们有理由怀疑概率分布的假设。在统计检验中,这些不可能的结果被称为否定域。如果这样的结果确实发生,我们将否定这个假设;概率分布的具体形式由假设决定,并且必须有多于一个。值得注意的是,这个假设只能被测试,并且从未被证实。统计检验可以帮助我们否定假设,但它不能帮助我们确认一个假设。为了使检验更加严谨和科学,需要更多的东西。首先,我们必须确定冒犯第一类![]() 和第二类错误的风险程度,其次,确定否定域是否应包含抽样分布的结尾。
和第二类错误的风险程度,其次,确定否定域是否应包含抽样分布的结尾。
一般来说,估计第二类错误![]() 的概率是不可能的。第一类错误
的概率是不可能的。第一类错误![]() ,否则,提交第一类错误
,否则,提交第一类错误![]() 的概率是域中各种结果概率的总和。测试的重要性决定了否定域的大小。如果抽样分布是连续的,则否定域可以建立在它想要建立的任何级别上,否定域的大小可以与重要级别的要求一致(如在随后的正常检验中那样)。如果抽样分布不连续,我们应该使用累积概率方法来找到一组构成否定域的结果。也就是说,在已知的概率分布表上,两端最小概率的概率开始累积到中心,直到概率的总和略小于所选的显著水平。
的概率是域中各种结果概率的总和。测试的重要性决定了否定域的大小。如果抽样分布是连续的,则否定域可以建立在它想要建立的任何级别上,否定域的大小可以与重要级别的要求一致(如在随后的正常检验中那样)。如果抽样分布不连续,我们应该使用累积概率方法来找到一组构成否定域的结果。也就是说,在已知的概率分布表上,两端最小概率的概率开始累积到中心,直到概率的总和略小于所选的显著水平。
在很多场合,我们可以预测偏差的方向,或者只对一个方向的偏差感兴趣。当方向可以预测时,在同一显著水平的条件下,单侧检验比双侧检验更合适。由于否定域集中在取样分布的更适当的一侧,因此可以获得相对较大的尾端。这样可以降低承认第二种类型错误![]() 的风险,就像第一种类型错误
的风险,就像第一种类型错误![]() 的风险不变一样。
的风险不变一样。
(4)根据所选择的显著水平![]() ,确定临界值和拒绝域
,确定临界值和拒绝域
完成上述工作后,下一步是尽可能做相同的实际样本(如重复投掷硬币的实际实验),并根据获得的样本数据计算检验统计量。检验统计数据是样本的综合指标,但与第四章参数估计中要讨论的统计数据不同,后者不用作估计数据,而仅用作检验。
(5)把检验统计量的值与临界值进行比较
如果统计值落在拒绝区域内(包括临界值),原假设与样本描述之间存在显著差异,原假设应该被拒绝,并且如果它落在接收域内,样本描述与原假设之间的差异不明显,原假设应该被接受。一般来说,如果你想否定最初的假设![]() ,只需要一个反例即可。
,只需要一个反例即可。
(6)作出接受或拒绝原假设的统计决策
否定论证是假设检验的一个重要推理方法,其目的在于假设原假设得以确立,如果观察到的数据的性能与假设相矛盾,则原假设被否定。通常使用的标准是小概率事件的实际推理原则。假设检验意味着拒绝或保留原假设的判断,也称为显著性检定。在选择否定域并计算检验统计量后,我们完成最后一个程序,即根据检验或样本结果确定案例的假设。如果结果落在否定域范围内,我们将在已知承诺第一类错误概率的条件下否定零假设。相反,如果结果落在定域外之外,那么零假设不会被否定,同时我们有可能犯第二类错误。
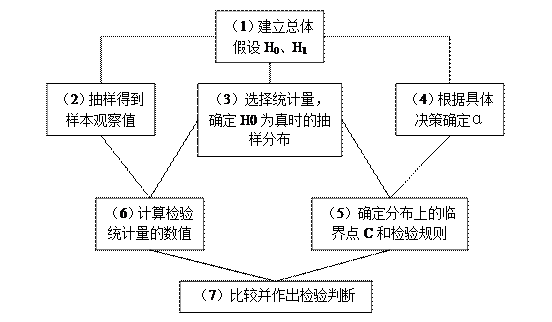
图5-7 假设检验的一般步骤
假设检验应注意的问题:
1.在做假设检验之前,应该注意数据本身是否具有可比性。
2.当差异有统计学意义时应注意这种差异在实际应用中无意义。
3.根据数据类型和特征使用正确的假设检验方法。
4.根据专业和经验确定是否选择单侧测试或双侧测试。
5.当测试结果是拒绝零假设时,应注意第一类错误的可能性,即它自己建立的错误拒绝![]() ,事先知道这种错误的可能性,即检查水平如此之大;当测试结果不是拒绝无效假设时,我们应该注意第二类错误的可能性。仍然有可能错误地认为
,事先知道这种错误的可能性,即检查水平如此之大;当测试结果不是拒绝无效假设时,我们应该注意第二类错误的可能性。仍然有可能错误地认为![]() 是不成立的,事先不知道这种错误的可能性,但它必须处理样本和I型错误的大小有关系。
是不成立的,事先不知道这种错误的可能性,但它必须处理样本和I型错误的大小有关系。
6.判断结论不能是绝对的,要注意接受或拒绝测试假设,否则有错误判断的可能。
7.报告结论应注意统计数据的使用,单边和双边的检验以及P值的确切范围。
假设检验与置信区间的关系:
假设检验与置信区间有密切的联系,我们往往可以由某参数的显著性水平为![]() 的检验,得到该参数的置信度为1-
的检验,得到该参数的置信度为1-![]() 的置信区间,反之亦然。例如,显著性水平
的置信区间,反之亦然。例如,显著性水平![]() 的均值μ的双侧检验问题:
的均值μ的双侧检验问题:
![]() :
: ![]() =
= ![]() ,
,![]() :
: ![]() ≠
≠![]()
与置信度为1-![]() 的置信区间之间有着这样的关系;若检验在
的置信区间之间有着这样的关系;若检验在![]() 水平下接受
水平下接受![]() ,则
,则![]() 的1-
的1-![]() 的置信区间必须包含
的置信区间必须包含![]() ;反之,若检验在
;反之,若检验在![]() 水平下拒绝
水平下拒绝![]() ,则
,则![]() 的1-
的1-![]() 的置信区间必定不包含
的置信区间必定不包含![]() 。
。
因此,我们可以用构造![]() 的1-
的1-![]() 置信区间的方法来检验上述假设,如果构造出来的置信区间包含
置信区间的方法来检验上述假设,如果构造出来的置信区间包含![]() ,就接受
,就接受![]() ;如果不包含
;如果不包含![]() 就拒绝
就拒绝![]() 。
。
同样给定显著水平![]() ,可以从构造检验规则的过程中,得到
,可以从构造检验规则的过程中,得到![]() 的1-
的1-![]() 置信区间。
置信区间。

