自动识别采集
上一节
下一节
自动识别采集
当我们的模板不能满足我们需求的时候,我们可以采用智能识别方法,简单方便还好用,快来学学吧!
智能识别采集
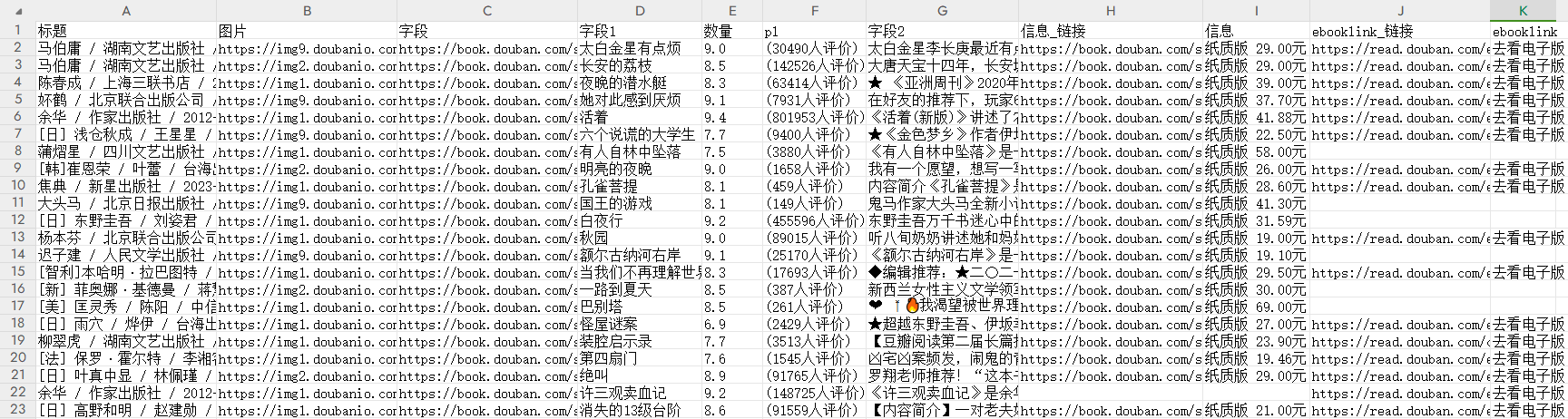
在主页的搜索框内输入我们要采集的网址(示例网址:https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4 )
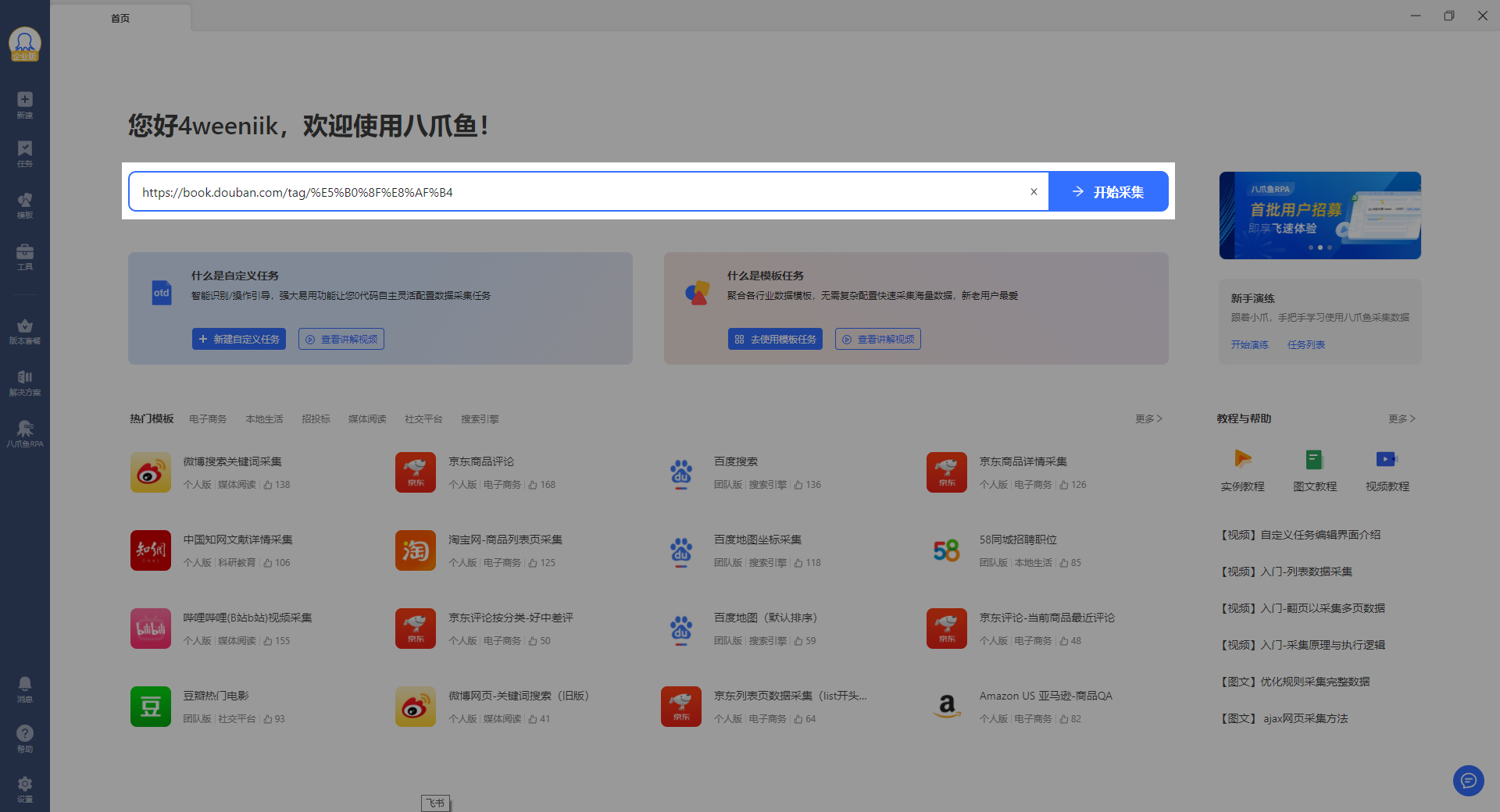
进入到自定义编辑页面以后,点击右上角黄色边框提示内的【自动识别网页内容】
系统会自动的识别网页数据配置采集规则
生成预设的采集规则以后,可以观察页面底部的数据字段是否与预期一致,若不一致则选择【切换识别结果】,确定好采集字段后点击【生成采集设置】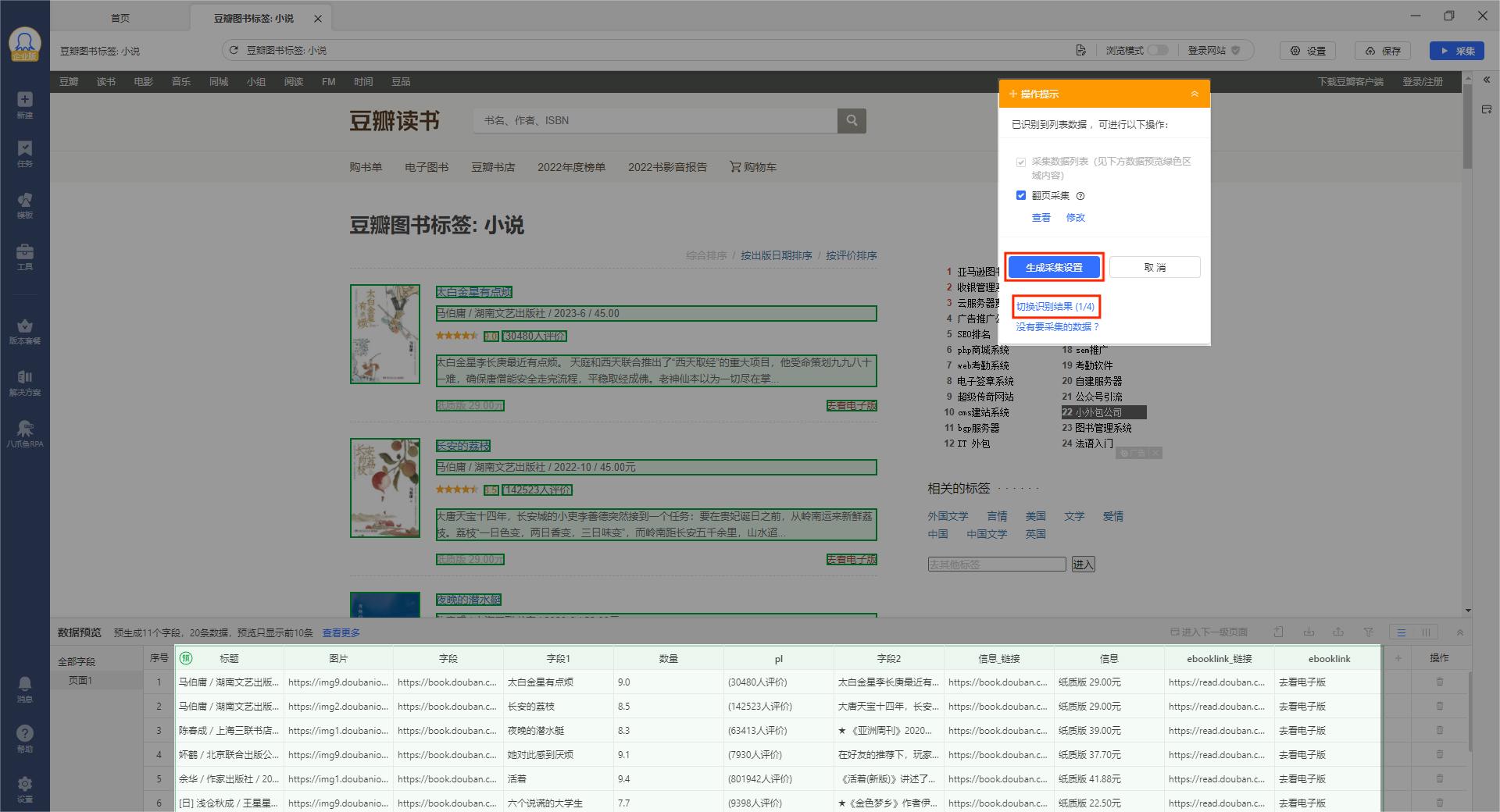
可以看到客户端右侧出现采集规则,底部绿色的预选字段变为白色
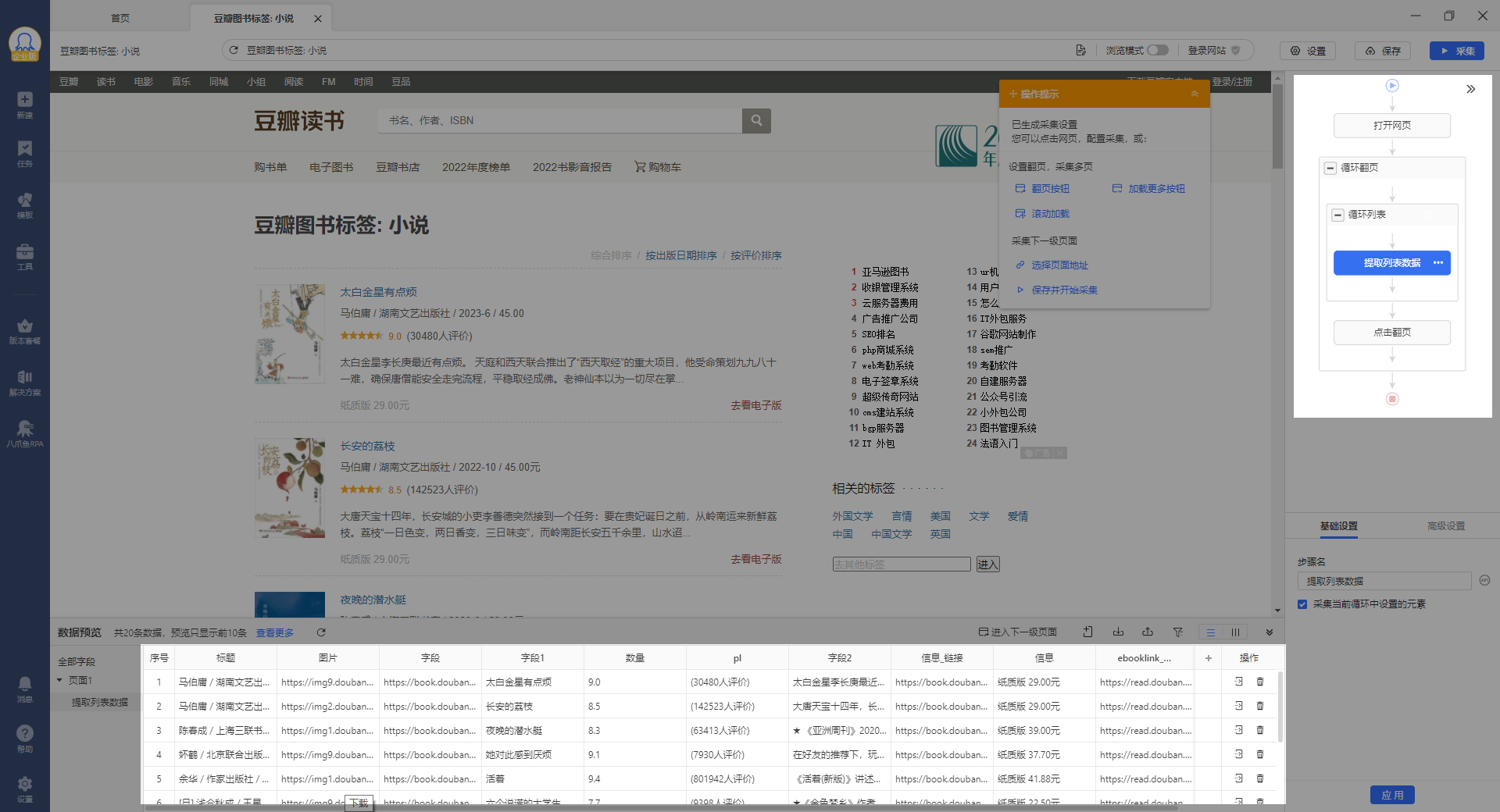
点击采集,启动采集页面
选择采集的方式,本地采集或云采集
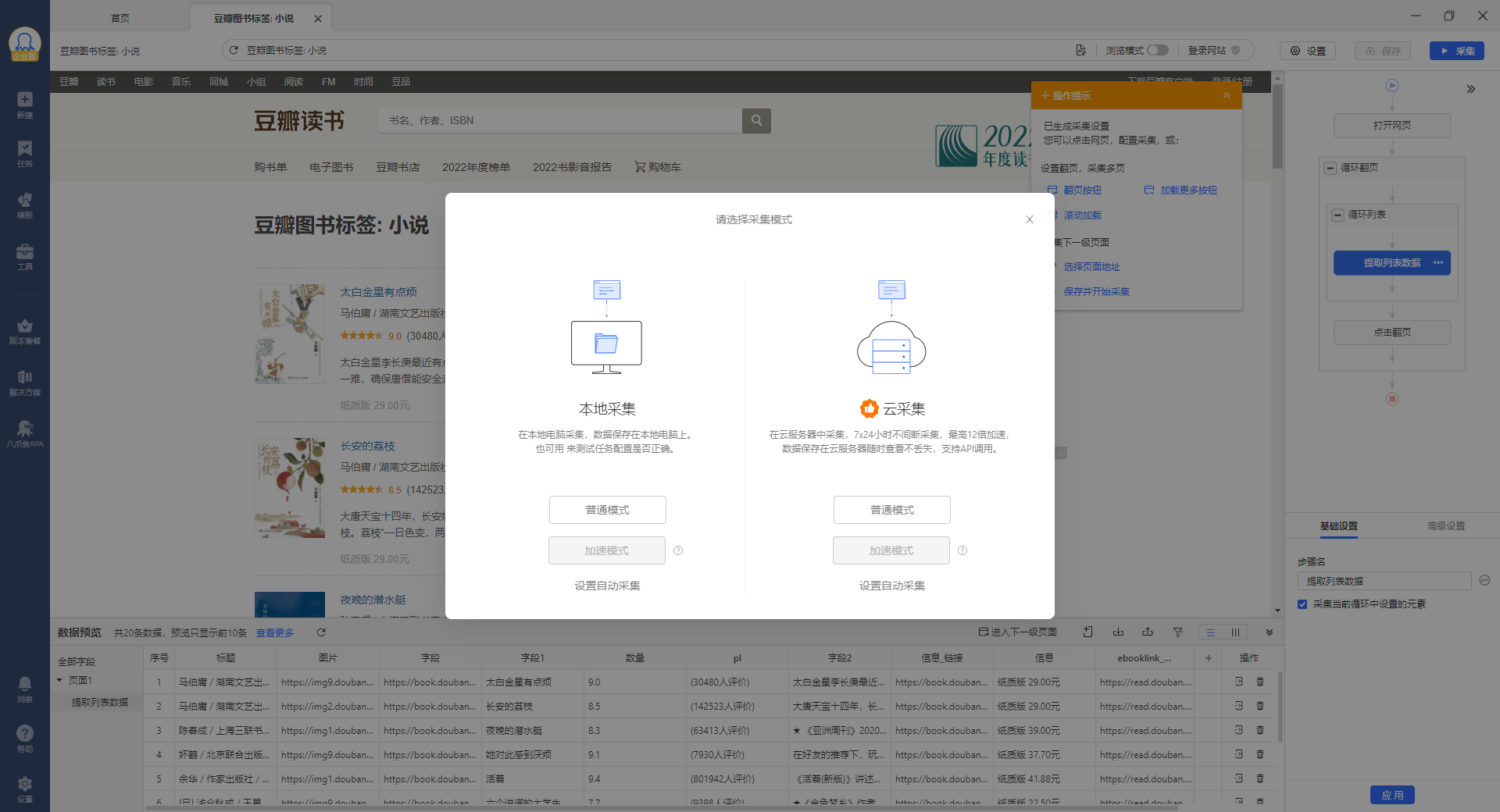
这里选择本地采集的普通模式,可以看到采集到数据啦!
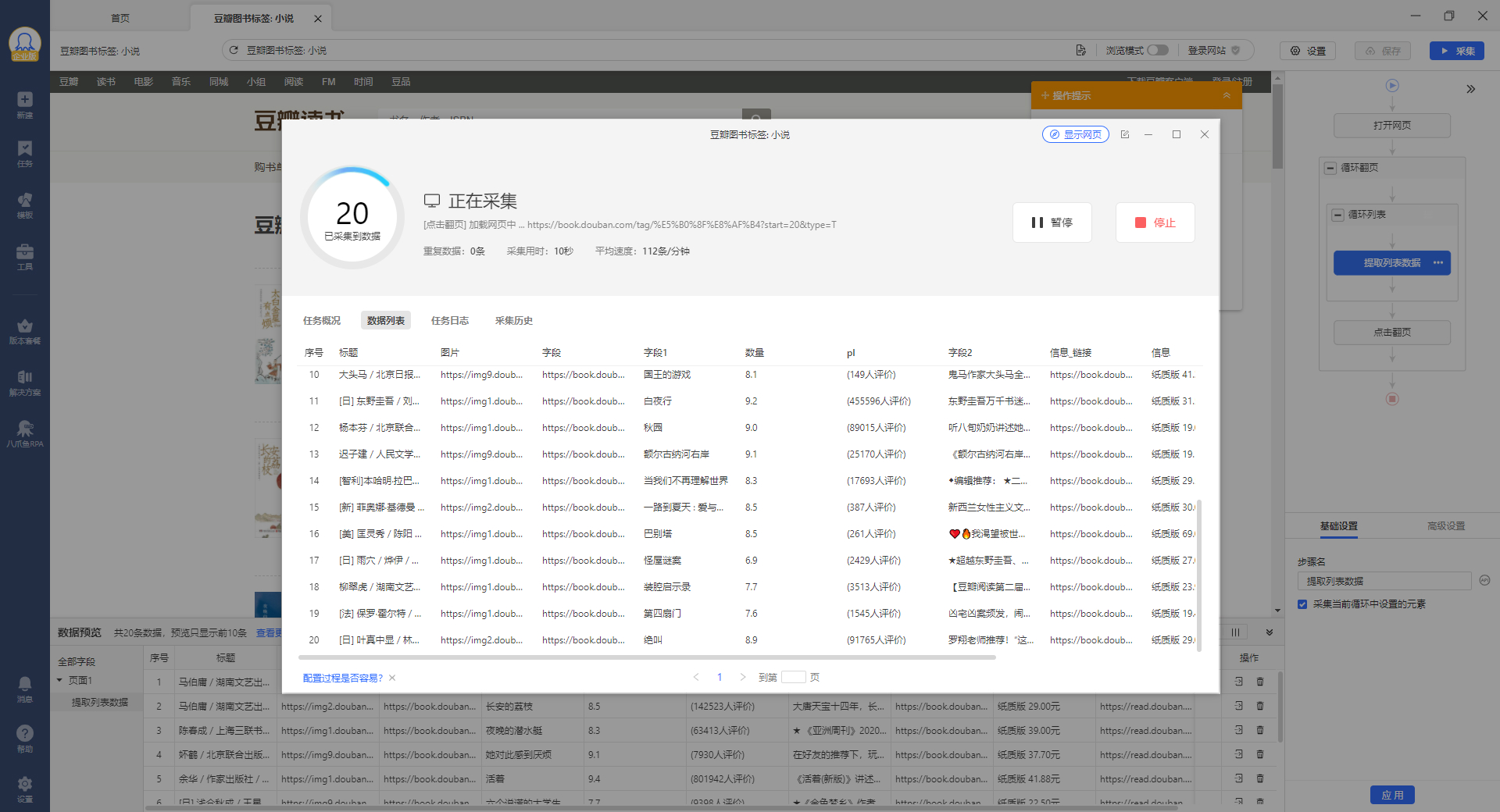
点击停止,导出数据
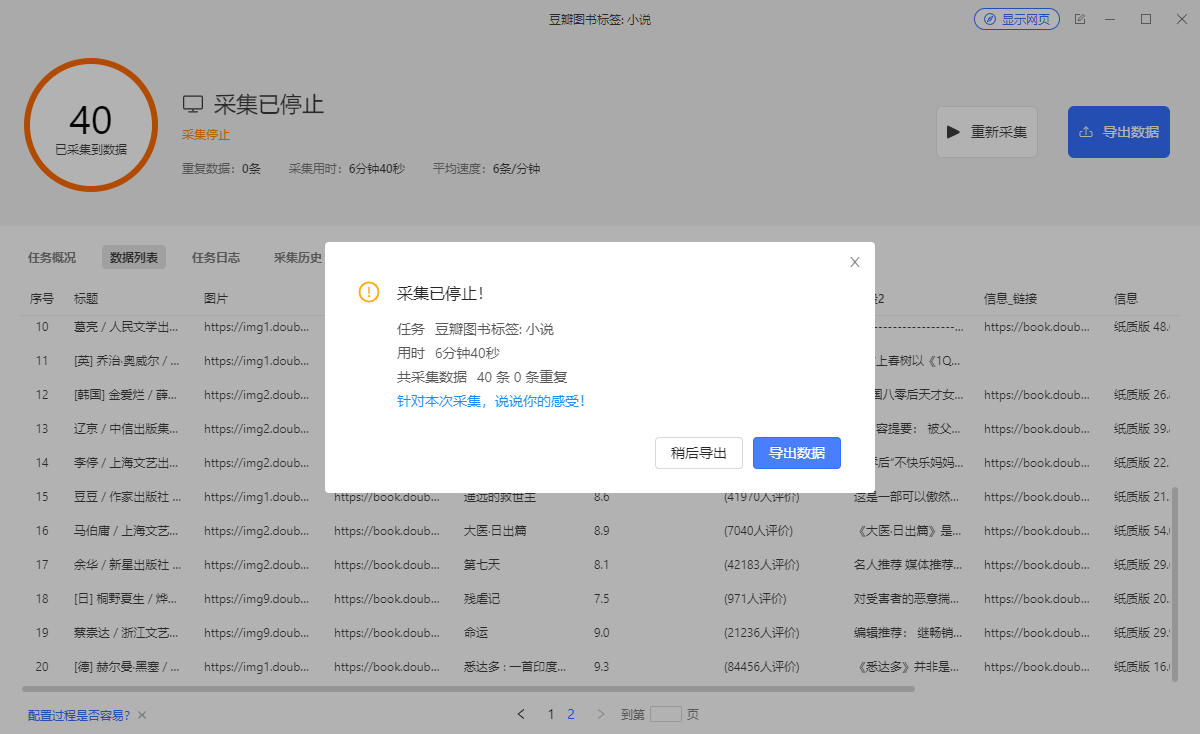
选择导出数据格式
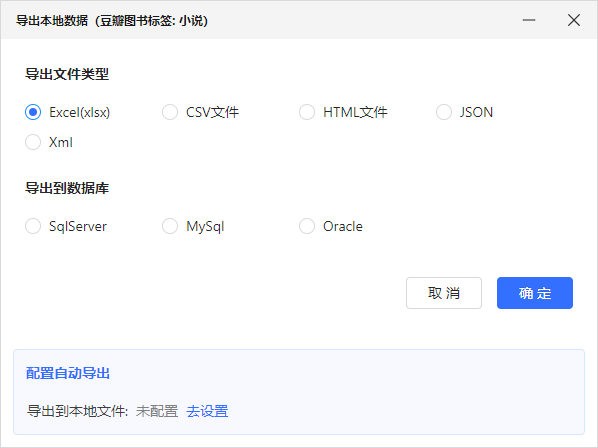
顺利采集到数据啦!